Year: 2017
My Fair Lady (1964)
The Heiress (1949)
Rogue One (2016)
server – Change Apache document root folder to secondary hard drive – Ask Ubuntu
» EtherCard library API » JeeLabs
EtherCard library API
In Software on Jun 19, 2011 at 00:01
As you may have noticed in the last few weblog posts, the API of the EtherCard library has changed quite a bit lately. I’m not doing this to be different, but as part of my never-ending quest to try and simplify the calling interface and to reduce the code size of the library (these changes shaved several Kb off the compiled code).
The main change was to switch to a single global buffer for storing an outgoing Ethernet packet and for receiving the next packet from the controller. This removes the need to pass a buffer pointer to almost each of the many functions in the library.
Buffer space is scarce on an ATmega, so you have to be careful not to run out of memory, while still having a sufficiently large buffer to do meaningful things. The way it works now is that you have to allocate the global buffer in your main sketch:

This particular style was chosen because it allows the library to access the buffer easily, and more importantly: without requiring an intermediate pointer.
To make this work, you have to initialize the EtherCard library in the proper way. This is now done by calling the begin() function as part of your setup() code:

The ether variable is defined globally in the EtherCard.h header file. The begin() call also needs the MAC address to use for this unit. The simplest way to provide that is to define a static array at the top of the sketch with a suitable value (it has to be unique on your LAN):
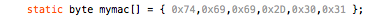
Next, you can use DHCP to obtain an IP address and locate the gateway and DNS server:
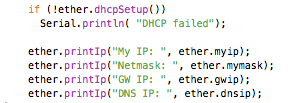
The printIp() utility function can optionally be used to print some info on the Serial port.
If you are going to set up a server, then a fixed IP address might be preferable. There’s a new staticSetup() function you can use when not doing DHCP:
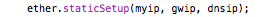
The gateway IP address is only needed if you’re going to access an IP address outside of your LAN, and the DNS IP addres is also optional (it’ll default to Google’s “8.8.8.8” DNS server if you do a DNS lookup). To omit values, pass a null pointer or leave the arguments off altogether:

Just remember to call either dhcpSetup() or staticSetup() after the begin() call.
DNS lookups are also very simple:
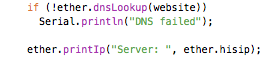
The one thing to keep in mind here, is that the website argument needs to be a flash-based string, which must be defined as follows:
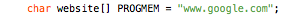
Note the “PROGMEM” modifier. See the Saving RAM space weblog post for more info about this technique.
This concludes the intialization part of the EtherCard library. Next, we need to keep things going by frequently polling for new incoming packets and responding to low-level ARP and ICMP requests. The easiest way to do so is to use the following template for loop():
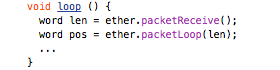
The packetReceive() function polls for new incoming data and copies it into the global buffer. The return value is the size of this packet (or zero if there is none).
The packetLoop() function looks at the incoming data and takes care of low-level responses. The return value is the offset in the global packet buffer where incoming TCP data can be found (or zero if there is none).
As to what to do next: it really all depends on what you’re after. Check out the examples in the Ethercard library for how to build web servers and web clients on top of this functionality.
To get an idea of the code overhead of the EtherCard library: a simple web client using DHCP and DNS is around 10 Kb, while an even simpler one using static IP addresses (no DHCP and no DNS) is under 7 Kb. The fairly elaborate EtherNode sample sketch, which includes DHCP and the RF12 library is now ≈ 13 Kb.
IOW, lots of room for adding your own app logic!
Fach
Fach
Method of classifying singers according to the range, weight, and color of their voices
This article is about music. For the Fuerza Aérea de Chile (FACh), see Chilean Air Force.
The German Fach system (German pronunciation: [fax]; literally “compartment” or “subject of study”, here in the sense of “vocal specialization”) is a method of classifying singers, primarily opera singers, according to the range, weight, and color of their voices. It is used worldwide, but primarily in Europe, especially in German-speaking countries and by repertory opera houses.
The Fach system is a convenience for singers and opera houses. It prevents a singer from being asked to sing roles which they are incapable of performing. Opera companies keep lists of available singers by Fach so that when they are casting roles for an upcoming production, they do not inadvertently contact performers who would be inappropriate for the part.
Below is a list of Fächer (German pronunciation: [ˈfɛçɐ]), their ranges as written on sheet music, and roles generally considered appropriate to each. When two names for the Fach are given, the first is in more common use today. Where possible, an English and/or Italian equivalent of each Fach is listed; however, not all Fächer have ready English or Italian equivalents. Note that some roles can be sung by more than one Fach and that many singers do not easily fit into a Fach: for instance some sopranos may sing both Koloratursopran and Dramatischer Koloratursopran roles. In addition, roles traditionally more difficult to cast may be given to a voice other than the traditional Fach. For instance, the “Queen of the Night” is more traditionally a dramatic coloratura role, but it is difficult to find a dramatic coloratura to sing it (particularly given the extreme range). Therefore, the role is often sung by a lyric coloratura.
15 Arias for Coloratura Soprano
15 Arias for colortura soprano
http://www.opera-arias.com/sheetmusic/15-arias-for-coloratura-soprano/
Percona
Percona is an open source software company specializing in MySQL, MongoDB, and other open source database support, consulting, managed services, and training. The company was founded in 2006 by Peter Zaitsev and Vadim Tkachenko[1][2] and is headquartered in Raleigh, North Carolina. The company launched a MySQL backup service in June 2014 as part of its managed services.[3] The company contributes to the open source MySQL community through its blog site, the MySQL Performance blog.[4] The company also hosts annual open source database user conferences[5] named “Percona Live” in Silicon Valley and Europe. The company’s founders have also published the O’Reilly book “High Performance MySQL.”[6]
The company builds and maintains free, open-source MySQL software for Percona Server, MySQL, and MariaDB users. Percona Server is a variant of the MySQL relational database management system and is a drop-in MySQL replacement.[7] The company also produces open source software including Percona XtraDB Cluster,[8] Percona XtraBackup and Percona Toolkit.
Source: Percona – Wikipedia
10 reasons to migrate to MariaDB (if still using MySQL) – Seravo
10 reasons to migrate to MariaDB (if still using MySQL)
![]() Out of distrust in Oracle stewardship of MySQL, the original developers of MySQL forked it and created MariaDB in 2009. As time passed, MariaDB replaced MySQL in many places and everybody reading this article should consider it too.
Out of distrust in Oracle stewardship of MySQL, the original developers of MySQL forked it and created MariaDB in 2009. As time passed, MariaDB replaced MySQL in many places and everybody reading this article should consider it too.
At Seravo, we migrated all of our own databases from MySQL to MariaDB in late 2013 and during 2014 we also migrated our customer’s systems to use MariaDB.
We recommend everybody still using MySQL in 2015 to migrate to MariaDB for the following reasons:
1) MariaDB development is more open and vibrant
Unlike many other open source projects Oracle inherited from the Sun acquisition, Oracle does indeed still develop MySQL and to our knowledge they have even hired new competent developers after most of the original developers resigned. The next major release MySQL 5.7 will have significant improvement over MySQL 5.6. However, the commit log of 5.7 shows that all contributors are @oracle.com. Most commit messages reference issue numbers that are only in an internal tracker at Oracle and thus not open for public discussion. There are no new commits in the latest 3 months because Oracle seems to update the public code repository only in big batches post-release. This does not strike as a development effort that would benefit from the public feedback loop and the Linus law of “given enough eyes all bugs are shallow”.
MariaDB on the other hand is developed fully in the open: all development decisions can be reviewed and debated on a public mailing list of in the public bug tracker. Contributing to MariaDB with patches is easy and patch flow is transparent in the fully public and up-to-date code repository. The Github statistics forMySQL 5.7 show 24 contributors while the equivalent figure for MariaDB 10.1 is 44 contributors. But it is not just a question of code contributors – in our experience MariaDB seems more active also in documentationefforts, distribution packaging and other related things that are needed in day-to-day database administration.
Because of the big momentum MySQL has had, there is still a lot of community around it but there is a clear trend that most new activities in the open source world revolve around MariaDB.
As Linux distributions play a major role in software delivery, testing and quality assurance, the fact that the both RHEL 7 and SLES 12 ship with MariaDB instead of MySQL increases the likelihood that MariaDB is going to be better maintained both upstream and downstream in years to come.
2) Quicker and more transparent security releases
Oracle only has a policy to make security releases (and related announcements) every three months for all of their products. MySQL however has a new release every two months. Sometimes this leads situations where security upgrades and security information are not synced. Also the MySQL release notes do not list all the CVE identifiers the releases fix. Many have complained that the actual security announcements are very vague and do not identify the actual issues or the commits that fixed them, which makes it impossible to do backporting and patch management for those administrators that cannot always simply upgrade to the latest Oracle MySQL release.
MariaDB however follows good industry standards by releasing security announcements and upgrades at the same time and handling the pre-secrecy and post-transparency in a proper way. MariaDB release notes also list the CVE identifiers pedantically and they even seem to update the release notes afterwards if new CVE identifiers are created about issues that MariaDB has already released fixes for.
3) More cutting edge features
MySQL 5.7 is looking promising and it has some cool new features like GIS support. However, MariaDB has had much more new features in recent years and they are released earlier, and in most cases those features seem to go through a more extensive review before release. Therefore we at Seravo trust MariaDB to deliver us the best features and least bugs.
For example GIS features were introduced already in the 5.3 series of MariaDB, which makes storing coordinates and querying location data easy. Dynamic column support (MariaDB only) is interesting because it allows for NoSQL type functionality, and thus one single database interface can provide both SQL and “not only SQL” for diverse software project needs.
4) More storage engines
MariaDB in particular excels as the amount of storage engines and other plugins it ships with: Connect and Cassandra storage engines for NoSQL backends or rolling migrations from legacy databases, Spider for sharding, TokuDB with fractal indexes etc. These plugins are available for MySQL as well via 3rd parties, but in MariaDB they are part of the official release, which guarantees that the plugins are well integrated and easy to use.
5) Better performance
MariaDB claims it has a much improved query optimizer and many other performance related improvements. Certain benchmarks show that MariaDB is radically faster than MySQL. Benchmarks don’t however always directly translate to real life situations. For example when we at Seravo migrated from MySQL to MariaDB, we saw moderate 3-5 % performance improvements in our real-life scenarios. Still, when it all adds up, 5% is relevant in particular for web server backends, where every millisecond counts. Faster is always better, even if it is just a bit faster.
6) Galera active-active master clustering
Galera is a new kind of clustering engine which, unlike traditional MySQL master-slave replication, provides master-master replication and thus enables a new kind of scalability architecture for MySQL/MariaDB. Despite that Galera development already started in 2007, it has never been a part of the official Oracle MySQL version while both Percona and MariaDB flavors have shipped a Galera based cluster version for years.
Galera support will be even better in MariaDB 10.1, as it will be included in the main version (and not anymore in a separate cluster version) and enabling Galera clustering is just a matter of activating the correct configuration parameters in any MariaDB server installation.
7) Oracle stewardship is uncertain
Many people have expressed distrust in Oracle’s true motivations and interest in keeping MySQL alive. As explained in point 1, Oracle wasn’t initially allowed to acquire Sun Microsystems, which owned MySQL, due to the EU competition legislation. MySQL was the biggest competitor to Oracle’s original database. The European Commission however approved the deal after Oracle published an official promise to keep MySQL alive and competitive. That document included an expiry date, December 14th 2014, which has now passed. One can only guess what the Oracle upper management has in mind for the future of MySQL.
Some may argue that in recent years, Oracle has already weakened MySQL in subtle ways. Maybe, but in Oracle’s defense, it should be noted that MySQL activities have been much more successful than for example OpenOffice or Hudson, which both very quickly forked into LibreOffice and Jenkins with such a momentum, that the original projects dried up in less than a year.
However, given the choice between Oracle and a true open source project, the decision should not be hard for anybody who understands the value of software freedom and the evolutive benefits that stem from global collaborative development.
8) MariaDB has leapt in popularity
In 2013 there was news about Wikipedia migrating it’s enormous wiki system from MySQL to MariaDB and about Google using MariaDB in their internal systems instead of MySQL. One of the MariaDB Foundation sponsors is Automattic, the company behind WordPress.com. Other notable examples are booking.com andCraigslist. Fedora and OpenSUSE have had MariaDB as the default SQL database option for years. With the releases of Red Hat Enterprise Linux 7 and SUSE Enterprise Linux 12 both these vendors ship MariaDB instead of MySQL and promises to support their MariaDB versions for the lifetime of the major distribution releases, that is up to 13 years.
The last big distribution to get MariaDB was Debian (and based on it, Ubuntu). The “intent to package” bugin Debian was already filed in 2010 but it wasn’t until December 2013 that the bug finally got closed. This was thanks to Seravo staff who took care of packaging MariaDB 5.5 for Debian, from where it also got into Ubuntu 14.04. Later we have also packaged MariaDB 10.0, which will be included in the next Debian and Ubuntu releases in the first half of 2015.
9) Compatible and easy to migrate
MariaDB 5.5 is a complete drop-in-replacement for MySQL 5.5. Migrating to MariaDB is as easy as runningapt-get install mariadb-server or the equivalent command on your chosen Linux flavor (which, in 2015, is likely to include MariaDB in the official repositories).
Despite the migration being easy, we still recommend that database admins undertake their own testing and always back up their databases, just to be safe.
10) Migration might become difficult after 2015
In versions MariaDB 10.0 and MySQL 5.6 the forks have already started to diverge somewhat but most likely users can still just upgrade from 5.6 to 10.0 without problems. The compatibility between 5.7 and 10.1 in the future is unknown, so the ideal time to migrate is now while it is still hassle-free. If binary incompatibilities arise in the future, database admins can always still migrate their data by dumping it and importing it in the new database.
With the above in mind, MariaDB is clearly our preferred option.
One of our customers once expressed their interest in migrating from MySQL to MariaDB and wanted us to confirm whether MariaDB is bug-free. Tragically we had to disappoint them with a negative answer. However we did assure them that the most important things are done correctly in MariaDB making it certainly worth migrating to.
Source: 10 reasons to migrate to MariaDB (if still using MySQL) – Seravo
themes – How to make Qt programs look good under Xfce? – Ask Ubuntu

I use Xfce.
My problem is – some programs look nice and some sort of ugly. AFAIK this is because Xfce is GTK and most programs use GTK theme, but some programs use Qt and thus don’t use GTK themes.
So – my question is – How can I apply some theme to these Qt programs? Can I download some qt theme and drop into ~/.themes? would that work? Qt programs don’t have to look absolutely the same as GTK ones – I don’t care about that. But I want them at least not to look so ugly.:)
Source: themes – How to make Qt programs look good under Xfce? – Ask Ubuntu