Build a highly available architecture
High availability (HA) ensures your architecture can handle failures. Imagine you’re responsible for a system that must be always fully operational. Failures can and will happen, so how do you ensure that your system can remain online when something goes wrong? How do you perform maintenance without service interruption?
Here, you’ll learn the need for high availability, evaluate application high-availability requirements, and see how the Azure platform helps you meet your availability goals.
What is high availability?
A highly-available service is a service that absorbs fluctuations in availability, load, and temporary failures in dependent services and hardware. The application remains online and available (or maintains the appearance of it) while performing acceptably. This availability is often defined by business requirements, service-level objectives, or service-level agreements.
High availability is ultimately about the ability to handle the loss or severe degradation of a component of a system. This might be due to a virtual machine that’s hosting an application going offline because the host failed. It could be due to planned maintenance for a system upgrade. It could even be caused by the failure of a service in the cloud. Identifying the places where your system can fail, and building in the capabilities to handle those failures, will ensure that the services you offer to your customers can stay online.
High availability of a service typically requires high availability of the components that make up the service. Think of a website that offers an online marketplace to purchase items. The service that’s offered to your customers is the ability to list, buy, and sell items online. To provide this service, you’ll have multiple components: a database, web servers, application servers, and so on. Each of these components could fail, so you have to identify how and where your failure points are, and determine how to address these failure points in your architecture.
Evaluate high availability for your architecture
There are three steps to evaluate an application for high availability:
- Determine the service-level agreement of your application
- Evaluate the HA capabilities of the application
- Evaluate the HA capabilities of dependent applications
Let’s explore these steps in detail.
Determine the service-level agreement of your application
A service-level agreement (SLA) is an agreement between a service provider and a service consumer in which the service provider commits to a standard of service based on measurable metrics and defined responsibilities. SLAs can be strict, legally bound, contractual agreements, or assumed expectations of availability by customers. Service metrics typically focus on service throughput, capacity, and availability, all of which can be measured in various ways. Regardless of the specific metrics that make up the SLA, failure to meet the SLA can have serious financial ramifications for the service provider. A common component of service agreements is guaranteed financial reimbursement for missed SLAs.
Service-level objectives (SLO) are the values of target metrics that are used to measure performance, reliability, or availability. These could be metrics defining the performance of request processing in milliseconds, the availability of services in minutes per month, or the number of requests processed per hour. By evaluating the metrics exposed by your application and understanding what customers use as a measure of quality, you can define the acceptable and unacceptable ranges for these SLOs. By defining these objectives, you clearly set goals and expectations with both the teams supporting the services and customers who are consuming these services. These SLOs will be used to determine if your overall SLA is being met.
The following table shows the potential cumulative downtime for various SLA levels.
Of course, higher availability is better, everything else being equal. But as you strive for more 9s, the cost and complexity to achieve that level of availability grows. An uptime of 99.99% translates to about 5 minutes of total downtime per month. Is it worth the additional complexity and cost to reach five 9s? The answer depends on the business requirements.
Here are some other considerations when defining an SLA:
- To achieve four 9’s (99.99%), you probably can’t rely on manual intervention to recover from failures. The application must be self-diagnosing and self-healing.
- Beyond four 9’s, it is challenging to detect outages quickly enough to meet the SLA.
- Think about the time window that your SLA is measured against. The smaller the window, the tighter the tolerances. It probably doesn’t make sense to define your SLA in terms of hourly or daily uptime.
Identifying SLAs is an important first step when determining the high availability capabilities that your architecture will require. These will help shape the methods you’ll use to make your application highly available.
Evaluate the HA capabilities of the application
To evaluate the HA capabilities of your application, perform a failure analysis. Focus on single points of failure and critical components that would have a large impact on the application if they were unreachable, misconfigured, or started behaving unexpectedly. For areas that do have redundancy, determine whether the application is capable of detecting error conditions and self-healing.
You’ll need to carefully evaluate all components of your application, including the pieces designed to provide HA functionality, such as load balancers. Single points of failure will either need to be modified to have HA capabilities integrated, or will need to be replaced with services that can provide HA capabilities.
Evaluate the HA capabilities of dependent applications
You’ll need to understand not only your application’s SLA requirements to your consumer, but also the provided SLAs of any resource that your application may depend on. If you are committing an uptime to your customers of 99.9%, but a service your application depends on only has an uptime commitment of 99%, this could put you at risk of not meeting your SLA to your customers. If a dependent service is unable to provide a sufficient SLA, you may need to modify your own SLA, replace the dependency with an alternative, or find ways to meet your SLA while the dependency is unavailable. Depending on the scenario and the nature of the dependency, failing dependencies can be temporarily worked around with solutions like caches and work queues.
Azure’s highly available platform
The Azure cloud platform has been designed to provide high availability throughout all its services. Like any system, applications may be affected by both hardware and software platform events. The need to design your application architecture to handle failures is critical, and the Azure cloud platform provides you with the tools and capabilities to make your application highly available. There are several core concepts when considering HA for your architecture on Azure:
- Availability sets
- Availability zones
- Load balancing
- Platform as a service (PaaS) HA capabilities
Availability sets
Availability sets are a way for you to inform Azure that VMs that belong to the same application workload should be distributed to prevent simultaneous impact from hardware failure and scheduled maintenance. Availability sets are made up of update domains and fault domains.
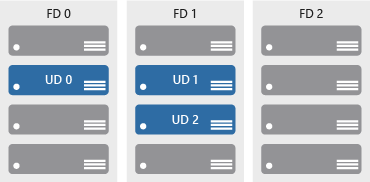
Update domains ensure that a subset of your application’s servers always remain running when the virtual machine hosts in an Azure datacenter require downtime for maintenance. Most updates can be performed with no impact to the VMs running on them, but there are times when this isn’t possible. To ensure that updates don’t happen to a whole datacenter at once, the Azure datacenter is logically sectioned into update domains (UD). When a maintenance event, such as a performance update and critical security patch that needs to be applied to the host, the update is sequenced through update domains. The use of sequencing updates using update domains ensures that the whole datacenter isn’t unavailable during platform updates and patching.
While update domains represent a logical section of the datacenter, fault domains (FD) represent physical sections of the datacenter and ensure rack diversity of servers in an availability set. Fault domains align to the physical separation of shared hardware in the datacenter. This includes power, cooling, and network hardware that supports the physical servers located in server racks. In the event the hardware that supports a server rack has become unavailable, only that rack of servers would be affected by the outage. By placing your VMs in an availability set, your VMs will be automatically spread across multiple FDs so that in the event of a hardware failure only part of your VMs will be impacted.
With availability sets, you can ensure your application remains online if a high-impact maintenance event is required or hardware failures occur.
Availability zones
Availability zones are independent physical datacenter locations within a region that include their own power, cooling, and networking. By taking availability zones into account when deploying resources, you can protect workloads from datacenter outages while retaining presence in a particular region. Services like virtual machines are zonal services and allow you to deploy them to specific zones within a region. Other services are zone-redundant services and will replicate across the availability zones in the specific Azure region. Both types ensure that within an Azure region there are no single points of failure.
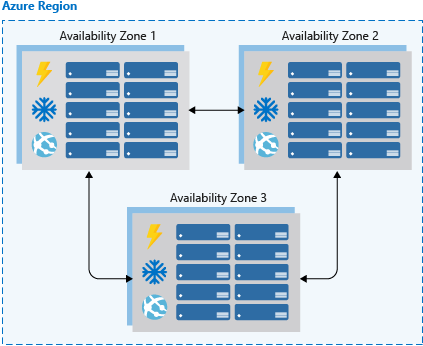
Supported regions contain a minimum of three availability zones. When creating zonal service resources in those regions, you’ll have the ability to select the zone in which the resource should be created. This will allow you to design your application to withstand a zonal outage and continue to operate in an Azure region before having to evacuate your application to another Azure region.
Availability zones are a newer high availability configuration service for Azure regions and are currently available for certain regions. It’s important to check the availability of this service in the region that you’re planning to deploy your application if you want to consider this functionality. Availability zones are supported when using virtual machines, as well as several PaaS services. Availability zones are mutually exclusive with availability sets. When using availability zones you no longer need to define an availability set for your systems. You’ll have diversity at the data center level, and updates will never be performed to multiple availability zones at the same time.
Load balancing
Load balancers manage how network traffic is distributed across an application. Load balancers are essential in keeping your application resilient to individual component failures and to ensure your application is available to process requests. For applications that don’t have service discovery built in, load balancing is required for both availability sets and availability zones.
Azure possesses three load balancing technology services that are distinct in their abilities to route network traffic:
- Azure Traffic Manager provides global DNS load balancing. You would consider using Traffic Manager to provide load balancing of DNS endpoints within or across Azure regions. Traffic manager will distribute requests to available endpoints, and use endpoint monitoring to detect and remove failed endpoints from load.
- Azure Application Gateway provides Layer 7 load-balancing capabilities, such as round-robin distribution of incoming traffic, cookie-based session affinity, URL path-based routing, and the ability to host multiple websites behind a single application gateway. Application Gateway by default monitors the health of all resources in its back-end pool and automatically removes any resource considered unhealthy from the pool. Application Gateway continues to monitor the unhealthy instances and adds them back to the healthy back-end pool once they become available and respond to health probes.
- Azure Load Balancer is a layer 4 load balancer. You can configure public and internal load-balanced endpoints and define rules to map inbound connections to back-end pool destinations by using TCP and HTTP health-probing options to manage service availability.
One or a combination of all three Azure load-balancing technologies can ensure you have the necessary options available to architect a highly available solution to route network traffic through your application.
PaaS HA capabilities
PaaS services come with high availability built in. Services such as Azure SQL Database, Azure App Service, and Azure Service Bus include high availability features and ensure that failures of an individual component of the service will be seamless to your application. Using PaaS services is one of the best ways to ensure that your architecture is highly available.
When architecting for high availability, you’ll want to understand the SLA that you’re committing to your customers. Then evaluate both the HA capabilities that your application has, and the HA capabilities and SLAs of dependent systems. After those have been established, use Azure features, such as availability sets, availability zones, and various load-balancing technologies, to add HA capabilities to your application. Any PaaS services you should choose to use will have HA capabilities built in.