\sloppy
Three terminal communication channel (van der Meulen)
1 Introduction
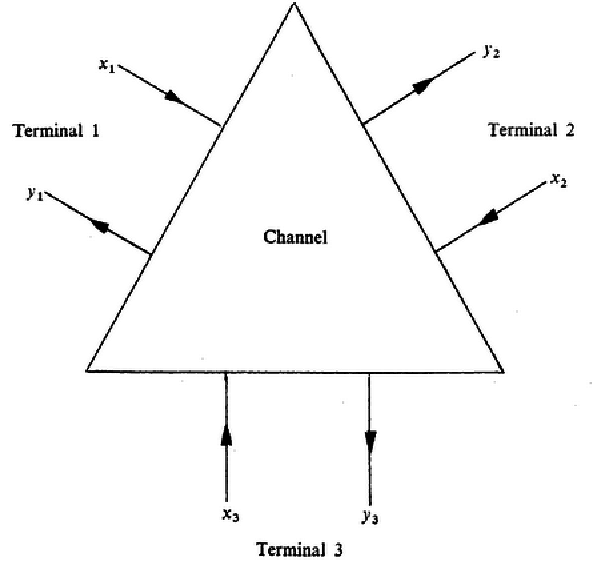
Formally, a discrete memoryless (d.m) three-terminal channel, denoted by P(y1, y2, y3|x1, x2, x3) consist of three pairs (At, Bt) of finite sets having at ≥ 2, bt ≥ 2 elements, respectively, and a collection of probability distributions on B1xB2xB3, one for each input (x1, x2, x3) ∈ A1xA2xA3, such that
2 Transmission along subchannels
Consider now the problem of sending information at a positive rate from terminal 1 to terminal 3, say, through a channl which has three different terminals. We are interested in determining which is the best way, i.e., what is the highest rate that can be achieved for sending in the 1-3 direction with arbitrary small probability of error.
A subchannel is a one-way channel which can be derived form the channel P(y1, y2, y3|x1, x2, x3) by keeping the input letter at one or two terminals fixed and by varying the inputs at the remaining terminals. We only consider those sub-channels which can be used to send information away from terminal 1, or to send information into terminal 3.
Let channel \strikeout off\uuline off\uwave offP(y1, y2, y3|x1, x2, x3) be given. We consider five kinds of subchannels:
(i) For each fixed pair (x2, x3) for inputs define a discrete memoryless one-way channel (d.m.c) \strikeout off\uuline off\uwave offP(y3|x1|x2, x3) with inputs x1 and outputs y3 by:\uuline default\uwave default
Let C1(1, 3|x2, x3) be its capacity and C1(1, 3) = maxx2, x3C1(1, 3|x2, x3).
(ii) Similarly
Let C1(1, 2|x2, x3) be its capacity and C1(1, 2) = maxx2, x3C1(1, 2|x2, x3).
(iii) For each pair (x2, x3) define a d.m.c P(y2, y3|x1|x2, x3) with inputs x1 and pair of outputs (y2, y3) by:
Denote its capacity with C1[1, (2, 3)|x2, x3] and define:
(iv) For each fixed pair (x1, x3) define a d.m.c \strikeout off\uuline off\uwave offP(y3|x2|x1, x3) with inputs x2 and outputs y3 by:
Let C1(2, 3|x1, x3) be its capacity and C1(2, 3) = maxx1, x3C1(2, 3|x1, x3)
(v) For each fixed input letter x3 define a d.m.c \strikeout off\uuline off\uwave offP(y3|x1, x2|x3) with pairs of inputs (x1, x2) and outputs y3 by:
Denote its capacity with C1[(1, 2), 3|x2, x3] and define:
To each of the above subchannels we have associated a channel capacity. This means one may apply the fundamental coding theorem for a d.m. channel which was first formulated by Shannon. It states that one may transmit over the channel at a rate arbitrarily close to the capacity with arbitrarily small probability of error by using the channel sufficiently many times.
The operation of a channel of the form P(y2, y3|x1|x2, x3) may be interpreted as follows. Imagine terminals 2 and 3 located at the same place. A pair of symbols (y2, y3) then becomes a single output to the channel. Interpreted this way, the d.m.c \strikeout off\uuline off\uwave offP(y2, y3|x1|x2, x3) can be used to send information form terminal 1 o the \uuline default\uwave defaultpair\strikeout off\uuline off\uwave off of terminals (2,3).
3 Examples of three-terminal channels
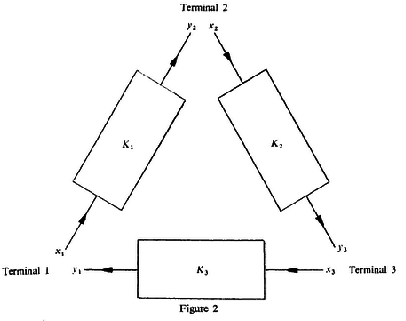
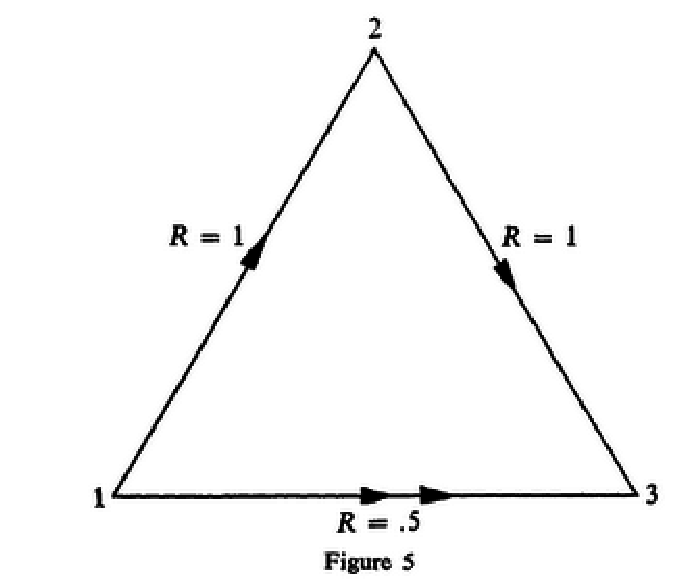
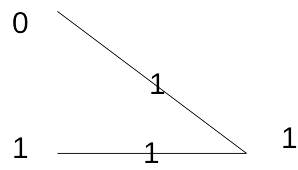
In 2↑ the three-terminal channel decomposes into three independent noiseless one-way channels with binary inputs and outputs. The operation of the channel is: y2 = x1; y3 = x2; y1 = x3; . The problem is how to comunicate form Therminal 1 to Therminal 3 as effectively as posible. Since y3 = x2 the inputs x1 at thermonal 1 cannot influence the outputs at y3 into one single opration i.e. C1(1, 3) = 0. However, terminal 1 can transmit at rate one to terminal 2 using channel K1 and terminal 2 can send at rate one to terminal 3 using channel K2. Thus terminal 1 can transmit information to terminal 3 by first sending to teminal 2 who then sends the recieved infomation on to terminal 3. In fact, since the operations of channels K1 and K2 are independent, terminal 1 and terminal 2 can transmit simultaneosuly and therefore terminal 1 can sent to terminal 3 at rate arbitrary close to one with zero error probability by using blocks of sufficient length n (MMV).
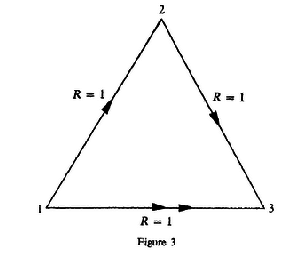
We have sumarized this results in 3↑. The double arrow indicates that a rate arbitrarry close to one in the 1-3 direction can be attained only if two channel operatios are allowed for the transmission of each single letter form terminal 1 to terminal 3.
(4↓) is generalization of an example given by Shannon [6] of a two-way channel, so-called modulo2 adder.
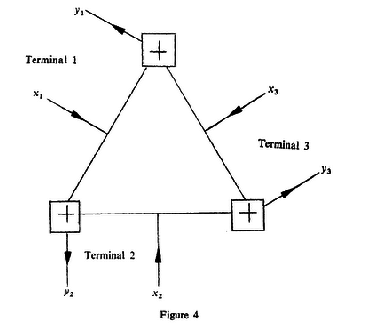
The inputs and outputs at each terminal are again x1 + x2 = y2(mod 2) x2 + x3 = y3(mod 2) x1 + x3 = y1(mod 2) . As the previous example, this three-terminal channl can be thougth as composed of three independent one-way noisless binary channels. In order to determine at terminal 2 the transmitted x1 one needs to add (mod 2) the just transmitted x2 to the observed y2. To each input letter x2 there corresponds a noisless one-way channel for sending from terminal 1 to terminal 3. Thus terminal 1 can send at rate one to terminal 2 and independently terminal 2 can send at rate one to treminal 3, i.e., C1(1, 2) = C1(2, 3) = 1. But then again terminial 1 can send to terminal 3 at rate arbitrary close to one with zero error probability, by first sending information at rate one to terminal 2 who then sends this information at the same rate on to terminal 3
(суштината е што терминал 2 не чека цела поворка да ја прати тој прима и одма праќа, само за првиот симбол имаш доцнење, другите одат едно за друго).
As in the previous example it is not possible for the inputs at terminal 1 to influence the outpust at terminal 3 in one single transmission period, i.e., C1(1, 3) = 0.
In the third example terminal 1 can choose between two different methods
Двата примери во Example3 се: 1. Праќаш од 1-3 2. Праќаш од 1-2 па потоаа од 2-3
for transmitting information to terminal 3. Here the input letters x1, x2, and x3 all belong to a ternary alphabet whereas the output letter y1, y2, y3 are all binary. Suppose that channel probabilities \strikeout off\uuline off\uwave offP(y1, y2, y3|x1, x2, x3) \uuline default\uwave defaultare the same for different x3\strikeout off\uuline off\uwave off and are given by Table I.
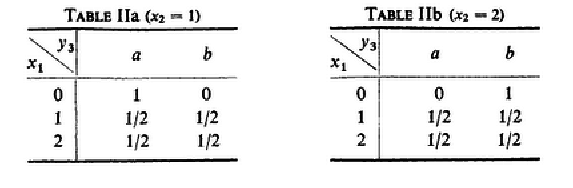
The corresponding marginal conditional probabilities P(y3|x1|x2) for sending from terminal 1 to terminal 3 if x2 is held at the letters 1 or 2 respectively are given in Tables IIa and IIb (овие табели се изведени директно од 1↑ само ги набљудуваш оние колони од табелтата за кои x2 одговара на зададената вредност).
-Иницијални изведувања:
P(y3|x1 = 0|x2 = 1) = b⎲⎳y3 = ap(Y3, X1 = 0, x2 = 1) = 1 + 0 = 1
\strikeout off\uuline off\uwave off
P(y3|x1 = 1|x2 = 1) = b⎲⎳y3 = ap(Y3, X1 = 0, x2 = 1) = (1)/(2) + (1)/(2) = 1
P(y3|x1 = 2|x2 = 1) = b⎲⎳y3 = ap(Y3, X1 = 2, X2 = 1) = (1)/(2) + (1)/(2) = 1
P(x1, y3|x2 = 1) = p(x1 = 0)⋅P(y3|x1 = 0|x2 = 1) + p(x1 = 1)⋅P(y3|x1 = 1|x2 = 1) + p(x1 = 2)⋅P(y3|x1 = 2|x2 = 1) = p(x1) + p(x2) + p(x3) = 1
P(x1, y3|x2 = 2) = p(x1 = 0)⋅P(y3|x1 = 0|x2 = 2) + p(x1 = 1)⋅P(y3|x1 = 1|x2 = 2) + p(x1 = 2)⋅P(y3|x1 = 2|x2 = 2) = p(x1) + p(x2) + p(x3) = 1
P(x1, x2, y3) = p(x2 = 1)⋅P(x1, y3|x2 = 1) + p(x2 = 2)⋅P(x1, y3|x2 = 2) = p(x1) + p(x2) + p(x3) = 1
C
= max[H(Yn) − H(Yn|Xn)] = log(8) + ⎲⎳(x1x2x3;y1, y2, y3)P(Xn)P(Yn|Xn)⋅log(P(Yn|Xn))
− H(Yn|Xn) = 5⋅8⋅(1)/(64)⋅log((1)/(8)) + 4⋅4⋅(1)/(32)⋅log((1)/(4)) = 2.875
C = max[H(Yn) − H(Yn|Xn)] = log2(8) − 2.875 = 0.125
C1 = (max[H(Yn) − H(Yn|Xn)])/(3) = 0.0416666667 bits ⁄ transmission
-Во боксот долу се навраќам на два проблеми од книгата на Cover
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~recall from Textbook

 (a) Crossover probability
(a) Crossover probability
I(X1, X2;Y1, Y2) = ?
X1, X2|Y1Y2 01 10 11 00 00 1 0 0 0 01 0 1 0 0 10 0 0 1 0 11 0 0 0 1
X1, X2|Y1Y2 01 10 11 00 00 1 0 0 0 01 0 1 0 0 10 0 0 1 0 11 0 0 0 1
\strikeout off\uuline off\uwave offI(X1, X2;Y1, Y2) = H(Y1, Y2) − H(Y1, Y2|X1X2) = H(X1, X2) − H(X1, X2|Y1Y2)
C=max(I(X1, X2;Y1, Y2)) = log2(4) − 0 = 2 bits
(X1, X2) ∈ [00, 01, 10, 11] p(X1, X2) = [(1)/(4), (1)/(4), (1)/(4), (1)/(4)]
I(X1;Y1) = H(Y1) − H(Y1|X1) = log(2) − H(Y1|X1) uniform input distribution of symbols maximizes the entropy ⇒ output symbols are also uniformely distributed
(X1, X2) ∈ [00, 01, 10, 11] p(X1, X2) = [(1)/(4), (1)/(4), (1)/(4), (1)/(4)]
I(X1;Y1) = H(Y1) − H(Y1|X1) = log(2) − H(Y1|X1) uniform input distribution of symbols maximizes the entropy ⇒ output symbols are also uniformely distributed
\strikeout off\uuline off\uwave offH(Y1|X1) = ∑p(x1)⋅p(y1|x1)⋅log2(p(y1|x1))
H(Y1|X1) = p(x1 = 0)⋅H(Y1|X1 = 0) + p(x1 = 1)⋅H(Y1|X1 = 1) = p(x1 = 0)⋅1 + p(x1 = 1)⋅1 = 1
I(X1;Y1) = H(Y1) − H(Y1|X1); C = max[I(X1;Y1)] = log(2) − H(Y1|X1) = 1 − 1 = 0
I(X1;Y1) = H(Y1) − H(Y1|X1); C = max[I(X1;Y1)] = log(2) − H(Y1|X1) = 1 − 1 = 0
000
001
010
100
→ a1
111
110
101
011
→ a2
⎛⎜⎝ 3 2 ⎞⎟⎠ = (3!)/(2!) = (6)/(2) = 3 P(ϵ) = q = 1 − p P() = p
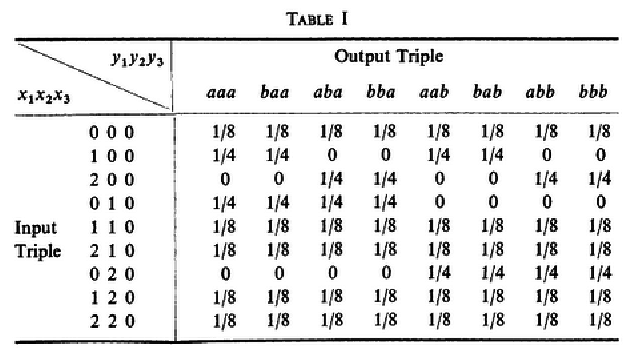
Crossover probability is:
P(a2|a1) = ∑3i = 2⎛⎜⎝ 3 i ⎞⎟⎠⋅qi⋅pi − 1 = ⎛⎜⎝ 3 2 ⎞⎟⎠⋅q2⋅p1 + ⎛⎜⎝ 3 3 ⎞⎟⎠⋅q3 = 0.0280000000
(b) Capacity of the channelI(X;Y) = H(Y) − H(Y|X); C = log2(2) − H(Y|X)⎛⎜⎝ 3 2 ⎞⎟⎠ = (3!)/(2!) = (6)/(2) = 3 P(ϵ) = q = 1 − p P() = p
Crossover probability is:
P(a2|a1) = ∑3i = 2⎛⎜⎝ 3 i ⎞⎟⎠⋅qi⋅pi − 1 = ⎛⎜⎝ 3 2 ⎞⎟⎠⋅q2⋅p1 + ⎛⎜⎝ 3 3 ⎞⎟⎠⋅q3 = 0.0280000000
\strikeout off\uuline off\uwave offH(Y|X) = P(000)⋅H(Y|000) + P(111)⋅H(Y|111) = 1 = P(a1)(0.028⋅log2(0.028) + .972⋅log2(.972)) + P(a2)(0.028⋅log2(0.028) + .972⋅log2(.972)) = 0.1842605934
\strikeout off\uuline off\uwave offC3 = log2(2) − H(Y|X) = 1 − 0.1842605934 = 0.8157394066
C = (C3)/(3) = (0.8157394066)/(3) = 0.2719131355333
(0.8157394066)/(3) = 0.2719131355333;
(0.8157394066)/(3) = 0.2719131355333;
(c) Original BSC
C = 1 − H(Y|X) = 1 − H(p) = 1 − 0.4689955936; 1 − 0.4689955936 = 0.5310044064
0.1log2(0.1) + 0.9log2(0.9) = − 0.4689955936
(d) Proof for any channel0.1log2(0.1) + 0.9log2(0.9) = − 0.4689955936
I(Xn;Yn) = H(Yn) − H(Yn|Xn) = H(Yn) − ∑ni = 1H(Yi|Yi − 11, Xn) ≤ |conditioning reduces entropy| ≤ ∑ni = 1H(Yi) − ∑ni = 1H(Yi|Yi − 11, Xn)
= ∑ni = 1H(Yi) − ∑ni = 1H(Yi|Xi) =
= n⋅I(X;Y) ⇒ I(Xn;Yn) ≤ n⋅I(X;Y) (I(Xn;Yn))/(n) ≤ I(X;Y) ⇒ (C(Xn, Yn))/(n) ≤ C(X, Y)
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
= ∑ni = 1H(Yi) − ∑ni = 1H(Yi|Xi) =
= n⋅I(X;Y) ⇒ I(Xn;Yn) ≤ n⋅I(X;Y) (I(Xn;Yn))/(n) ≤ I(X;Y) ⇒ (C(Xn, Yn))/(n) ≤ C(X, Y)
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-Повторно изведување во врска тврдењето во чланакот дека капацитетот на каналот е 0.32. Јас добивам дека е 0.28.
I(X1, X2;Y) = H(Y) − H(Y|X1X2); C = log(2) − H(Y|X1X2); H(Y|X1X2) = ?
p(xi = i) = pi, i = 0, 1, 2; p(y = a) = p(a); p(y = b) = p(b)
p(xi = i) = pi, i = 0, 1, 2; p(y = a) = p(a); p(y = b) = p(b)
1H(Y|X1X2)
= p(x2 = 1)⋅H(Y|X1, X2 = 1) + p(x2 = 2)⋅H(Y|X1, X2 = 2) = − p(x2 = 1)⋅{p(a|p0)log2p(a|p0) + p1⋅[p(a|p1)⋅log2p(a|p1) + p(b|p1)⋅log2p(b|p1)]
+ p2⋅[p(a|p2)log2(p(a|p2)) + p(b|p2)log2(p(b|p2))]} − p(x2 = 2){p(b|p0)log2p(b|p0) + p1⋅[p(a|p1)⋅log2p(a|p1) + p(b|p1)⋅log2p(b|p1)]
p2⋅[p(a|p2)log2(p(a|p2)) + p(b|p2)log2(p(b|p2))]} = p(x2 = 1){p1 + p2} + p(x2 = 2){p1 + p2} = p1 + p2
\strikeout off\uuline off\uwave offH(Y|X1X2) = p(X2 = 1){0 + p(X1 = 1)⋅1 + p(X1 = 2)⋅1} + p(X2 = 2){0 + p(X1 = 1)⋅1 + p(X1 = 2)⋅1} = p(X1 = 1) + p(X1 = 2)
I(X1, X2;Y) = H(Y) − H(Y|X1X2) = H(Y) − (p(X1 = 1) + p(X1 = 2))
C = log2(2) − (p(X1 = 1) + p(X1 = 2)) = | unifrom output symbols implay uniform inputs| = 1 − (2)/(3) = 0.33
C = log2(2) − (p(X1 = 1) + p(X1 = 2)) = | unifrom output symbols implay uniform inputs| = 1 − (2)/(3) = 0.33
y3|x1x2x3
a
b
000
1 ⁄ 2
1 ⁄ 2
100
1 ⁄ 2
1 ⁄ 2
200
1 ⁄ 2
1 ⁄ 2
010
1
0
110
1 ⁄ 2
1 ⁄ 2
210
1 ⁄ 2
1 ⁄ 2
020
0
1
120
1 ⁄ 2
1 ⁄ 2
220
1 ⁄ 2
1 ⁄ 2
\strikeout off\uuline off\uwave off
y2|x1x2x3
a
b
000
1 ⁄ 2
1 ⁄ 2
100
1
0
200
0
1
010
1 ⁄ 2
1 ⁄ 2
110
1 ⁄ 2
1 ⁄ 2
210
1 ⁄ 2
1 ⁄ 2
020
1 ⁄ 2
1 ⁄ 2
120
1 ⁄ 2
1 ⁄ 2
220
1 ⁄ 2
1 ⁄ 2
y1|x1x2x3
a
b
000
1 ⁄ 2
1 ⁄ 2
100
1 ⁄ 2
1 ⁄ 2
200
1 ⁄ 2
1 ⁄ 2
010
1 ⁄ 2
1 ⁄ 2
110
1 ⁄ 2
1 ⁄ 2
210
1 ⁄ 2
1 ⁄ 2
020
1 ⁄ 2
1 ⁄ 2
120
1 ⁄ 2
1 ⁄ 2
220
1 ⁄ 2
1 ⁄ 2
H(Y3|X1X2X3) = H(Y3|X1X2) = p(000)⋅1 + p(100)⋅1 + p(200)⋅1 + p(010)⋅0 + p(110)⋅1 + p(210)⋅1 + p(020)⋅0 + p(120)⋅1 + p(220)⋅1
C = H(Y3) − H(Y3|X1X2X3) = 1 − H(Y3|X1X2) = 1 − 7 ⁄ 9 = (2)/(9)
C = H(Y3) − H(Y3|X1X2X3) = 1 − H(Y3|X1X2) = 1 − 7 ⁄ 9 = (2)/(9)
\strikeout off\uuline off\uwave offH(Y1|X1X2X3) = H(Y3|X1X2) = p(000)⋅1 + p(100)⋅1 + p(200)⋅1 + p(010)⋅1 + p(110)⋅1 + p(210)⋅1 + p(020)⋅1 + p(120)⋅1 + p(220)⋅1 = 1
\strikeout off\uuline off\uwave offH(Y2|X1X2X3) = H(Y3|X1X2) = p(000)⋅1 + p(100)⋅0 + p(200)⋅0 + p(010)⋅1 + p(110)⋅1 + p(210)⋅1 + p(020)⋅1 + p(120)⋅1 + p(220)⋅1 = 1
C1(1, 3) = maxx2, x3C1(1, 3|x2, x3) ова е од дефиницијата во чланакот на van der Meulen
\strikeout off\uuline off\uwave offP(y3|x1|x2, x3) = ∑y1, y2P(y1, y2, y3|x1, x2, x3)
C1(1, 3) = max[I(X1;Y3)] = H(Y3) − H(Y3|X1) = log2(2) − p(x1 = 0)⋅0 − p(x2 = 1)⋅1 − p(x1 = 2)⋅1 = 1 − p(x1 = 1) − p(x1 = 2)
Значи и без да усреднуваш по x2 го добивам истиот резултат за капацитетот.
Значи и без да усреднуваш по x2 го добивам истиот резултат за капацитетот.
-
Сега ќе одам со Лагранжови мултипликатори
H(Y) = (2)/(3)log2(3)/(2) + (1)/(3)log23
(x1, y3) a b p(x1) 0 1 ⁄ 3 0 p 1 0.5 ⁄ 3 0.5 ⁄ 3 1 − p 2 0.5 ⁄ 3 0.5 ⁄ 3 0 p(y3) 1 ⁄ 2 1 ⁄ 2
(x1, y3) a b p(x1) 0 p0 0 p0 1 0.5⋅p1 0.5⋅p1 p1 2 0.5⋅p2 0.5⋅p2 p2 p(y3) 1 ⁄ 2 1 ⁄ 2
p0 + (p1)/(2) + (p2)/(2) = (1)/(2)
(p1)/(2) + (p2)/(2) = (1)/(2) → p2 = 1 − p1
p0 + p1 + p2 = 1 → p0 + p1 + 1 − p1 = 1 → p0 = 0 → C1(1, 3) = 0 → uniformna raspredelba na izleznite simboli ne go maksimizira kapacitetot
− H(Y) = p(y3 = a)⋅log2(p(y3 = a)) + p(y3 = b)⋅log2(p(y3 = b))
(x1, y3) a b p(x1) 0 1 ⁄ 3 0 p 1 0.5 ⁄ 3 0.5 ⁄ 3 1 − p 2 0.5 ⁄ 3 0.5 ⁄ 3 0 p(y3) 1 ⁄ 2 1 ⁄ 2
(x1, y3) a b p(x1) 0 p0 0 p0 1 0.5⋅p1 0.5⋅p1 p1 2 0.5⋅p2 0.5⋅p2 p2 p(y3) 1 ⁄ 2 1 ⁄ 2
p0 + (p1)/(2) + (p2)/(2) = (1)/(2)
(p1)/(2) + (p2)/(2) = (1)/(2) → p2 = 1 − p1
p0 + p1 + p2 = 1 → p0 + p1 + 1 − p1 = 1 → p0 = 0 → C1(1, 3) = 0 → uniformna raspredelba na izleznite simboli ne go maksimizira kapacitetot
− H(Y) = p(y3 = a)⋅log2(p(y3 = a)) + p(y3 = b)⋅log2(p(y3 = b))
p(y3 = a) = p(x1 = 0)⋅p(y = a|x1 = 0) + p(x1 = 1)⋅p(y = a|x1 = 1) + p(x1 = 2)⋅p(y = a|x1 = 2) = p0⋅p(y = a|x1 = 0) + p1⋅p(y = a|x1 = 1) + p2⋅p(y = a|x1 = 2) =
p(y3 = a) = p0 + (p1)/(2) + (p2)/(2)
p(y3 = b) = p0⋅p(y = b|p0) + p1⋅p(y = b|p1) + p2⋅p(y = b|p2) = (p1)/(2) + (p2)/(2) p(y3 = b) = (p1)/(2) + (p2)/(2) − H(Y) = ⎛⎝p0 + (p1)/(2) + (p2)/(2)⎞⎠log2⎛⎝p0 + (p1)/(2) + (p2)/(2)⎞⎠ + ⎛⎝(p1)/(2) + (p2)/(2)⎞⎠log2⎛⎝(p1)/(2) + (p2)/(2)⎞⎠
p0 = 1 − p1 − p2; − H(Y) = ⎛⎝1 − (p1)/(2) − (p2)/(2)⎞⎠log2⎛⎝1 − (p1)/(2) − (p2)/(2)⎞⎠ + ⎛⎝(p1)/(2) + (p2)/(2)⎞⎠log2⎛⎝(p1)/(2) + (p2)/(2)⎞⎠ = − H(p) H(Y) = H(p) where p = (p1)/(2) + (p2)/(2)
Ако ја земам дека униформната распределба ја максимизира ентропијата ќе добијам:
max[H(Y)] = H(p = (1)/(2)) ⇒ (p1)/(2) + (p2)/(2) = (1)/(2) ама оваа вредност ќе го направи I(X1, X2;Y) = 0
Затоа ќе одам со лагражнови мултипликатори:
I(X1, X2;Y) = H(Y) − H(Y|X1X2) = H(Y) − p(X1 = 1) − p(X1 = 2)
I(X1, X2;Y) = − ⎛⎝1 − (p1)/(2) − (p2)/(2)⎞⎠log2⎛⎝1 − (p1)/(2) − (p2)/(2)⎞⎠ − ⎛⎝(p1)/(2) + (p2)/(2)⎞⎠log2⎛⎝(p1)/(2) + (p2)/(2)⎞⎠ − p1 − p2
f(pi) = − ⎛⎝1 − (p1)/(2) − (p2)/(2)⎞⎠log2⎛⎝1 − (p1)/(2) − (p2)/(2)⎞⎠ − ⎛⎝(p1)/(2) + (p2)/(2)⎞⎠log2⎛⎝(p1)/(2) + (p2)/(2)⎞⎠ − p1 − p2 + λ∑3i = 1pi
(∂)/(∂pi)(f(pi)) = 0 (∂)/(∂p1)(f(pi)) = (1)/(2)⋅log2⎛⎝1 − (p1)/(2) − (p2)/(2)⎞⎠ − ⎛⎝1 − (p1)/(2) − (p2)/(2)⎞⎠⋅( − (1)/(2))/(ln(2)⋅ ⎛⎝1 − (p1)/(2) − (p2)/(2)⎞⎠) − (1)/(2)⋅log2⎛⎝(p1)/(2) + (p2)/(2)⎞⎠ − ⎛⎝(p1)/(2) + (p2)/(2)⎞⎠⋅((1)/(2))/(ln(2)⋅⎛⎝(p1)/(2) + (p2)/(2)⎞⎠) − 1 + λ = 0
I(X1, X2;Y) = H(Y) − H(Y|X1X2) = H(Y) − p(X1 = 1) − p(X1 = 2)
I(X1, X2;Y) = − ⎛⎝1 − (p1)/(2) − (p2)/(2)⎞⎠log2⎛⎝1 − (p1)/(2) − (p2)/(2)⎞⎠ − ⎛⎝(p1)/(2) + (p2)/(2)⎞⎠log2⎛⎝(p1)/(2) + (p2)/(2)⎞⎠ − p1 − p2
f(pi) = − ⎛⎝1 − (p1)/(2) − (p2)/(2)⎞⎠log2⎛⎝1 − (p1)/(2) − (p2)/(2)⎞⎠ − ⎛⎝(p1)/(2) + (p2)/(2)⎞⎠log2⎛⎝(p1)/(2) + (p2)/(2)⎞⎠ − p1 − p2 + λ∑3i = 1pi
(∂)/(∂pi)(f(pi)) = 0 (∂)/(∂p1)(f(pi)) = (1)/(2)⋅log2⎛⎝1 − (p1)/(2) − (p2)/(2)⎞⎠ − ⎛⎝1 − (p1)/(2) − (p2)/(2)⎞⎠⋅( − (1)/(2))/(ln(2)⋅ ⎛⎝1 − (p1)/(2) − (p2)/(2)⎞⎠) − (1)/(2)⋅log2⎛⎝(p1)/(2) + (p2)/(2)⎞⎠ − ⎛⎝(p1)/(2) + (p2)/(2)⎞⎠⋅((1)/(2))/(ln(2)⋅⎛⎝(p1)/(2) + (p2)/(2)⎞⎠) − 1 + λ = 0
(1)/(2)⋅log2⎛⎝1 − (p1)/(2) − (p2)/(2)⎞⎠ + (1)/(2⋅ln(2)) − (1)/(2)⋅log2⎛⎝(p1)/(2) + (p2)/(2)⎞⎠ − (1)/(2⋅ln(2)) − 1 + λ = 0 (1)/(2)⋅log2⎛⎝1 − (p1)/(2) − (p2)/(2)⎞⎠ − (1)/(2)⋅log2⎛⎝(p1)/(2) + (p2)/(2)⎞⎠ − 1 + λ = 0
(1)/(2)⋅log2(⎛⎝1 − (p1)/(2) − (p2)/(2)⎞⎠)/(⎛⎝(p1)/(2) + (p2)/(2)⎞⎠) − 1 + λ = 0 log2(⎛⎝1 − (p1)/(2) − (p2)/(2)⎞⎠)/(⎛⎝(p1)/(2) + (p2)/(2)⎞⎠) = 2(1 − λ) (⎛⎝1 − (p1)/(2) − (p2)/(2)⎞⎠)/(⎛⎝(p1)/(2) + (p2)/(2)⎞⎠) = 22(1 − λ) (1)/(⎛⎝(p1)/(2) + (p2)/(2)⎞⎠) − 1 = 22(1 − λ) (2)/((p1 + p2)) − 1 = 22(1 − λ) ((p1 + p2))/(2) = (1)/(1 + 22(1 − λ))
(p1 + p2) = (2)/(1 + 22(1 − λ)) p1 = (2)/(1 + 22(1 − λ)) − p2 for λ = 0 p1 = (2)/(5) − p2; p1 + p2 = (2)/(5) ⇒ p0 = 1 − (2)/(5) = (3)/(5) H(Y) = H((2)/(5)) = 0.9709505947
\mathnormalC2 = H((2)/(5)) − p1 − p2 = H((2)/(5)) − (2)/(5) = 0.5709505947C1 = (C2)/(2) = 0.2854752974
Ако земам λ = 1 ⁄ 2:
\mathnormalC2 = H((2)/(5)) − p1 − p2 = H((2)/(5)) − (2)/(5) = 0.5709505947C1 = (C2)/(2) = 0.2854752974
Ако земам λ = 1 ⁄ 2:
\strikeout off\uuline off\uwave off(p1 + p2) = (2)/(1 + 22(1 − λ)) = (2)/(3) ⇒ p0 = (1)/(3)
\strikeout off\uuline off\uwave off\mathnormalC2 = H((1)/(3))\mathnormal − (2)/(3) = 0.2516291674
Дефинитивно горното решение е подобро!!!!
-Ash проблем 3.7
Ден и пол се обидував да го решам и добијам резултатот \mathchoiceC1(1, 3) = 0.32C1(1, 3) = 0.32C1(1, 3) = 0.32C1(1, 3) = 0.32. На крај вредноста ја добив откако го видов решението во Textbook-от од Ash. Се работи за користење на резултатот од Теорема 3.3.3 од Ash (има и ваков проблем во Т. Cover EIT) .
⎡⎢⎣
p(y1)
p(y2)
⎤⎥⎦ = ⎡⎢⎣
α
1 − α
β
1 − β
⎤⎥⎦⎡⎢⎣
p(x1)
p(x2)
⎤⎥⎦
p1 = p(x1); p2 = p(x2);
I = H(Y) − H(Y|X); p(y1) = αp1 + (1 − α)⋅p2; p(y2) = β⋅p1 + (1 − β)⋅p2; H(Y) = (αp1 + (1 − α)⋅p2)log2⎛⎝(1)/(αp1 + (1 − α)⋅p2)⎞⎠ +
p1 = p(x1); p2 = p(x2);
I = H(Y) − H(Y|X); p(y1) = αp1 + (1 − α)⋅p2; p(y2) = β⋅p1 + (1 − β)⋅p2; H(Y) = (αp1 + (1 − α)⋅p2)log2⎛⎝(1)/(αp1 + (1 − α)⋅p2)⎞⎠ +
\strikeout off\uuline off\uwave off + (β⋅p1 + (1 − β)⋅p2)⋅log⎛⎝(1)/(β⋅p1 + (1 − β)⋅p2)⎞⎠
H(Y|X) = ∑2i = 1p(xi)⋅H(Y|xi) = p1⋅H(Y|p1) + p2⋅H(Y|p2) = − p(x1)⋅[p(y1|x1)⋅log2(p(y1|x1)) + p(y2|x1)⋅log2(p(y2|x1))]
− p(x2)⋅[p(y1|x2)⋅log2(p(y1|x2) + p(y2|x2)⋅log2(p(y2|x2))] = − p1(αlog(α) + β⋅log2β) − p2((1 − α)log(1 − α) + (1 − β)log2(1 − β))
Ако α = β = 1 ⁄ 2
I = − 2⎛⎝(p1)/(2) + (p2)/(2)⎞⎠log2⎛⎝(p1)/(2) + (p2)/(2)⎞⎠ − p1 − p2
f(p1, p2) = − 2⎛⎝(p1)/(2) + (p2)/(2)⎞⎠log2⎛⎝(p1)/(2) + (p2)/(2)⎞⎠ − p1 − p2 + λ⋅∑2i = 1pi
(∂)/(∂p1)(f(p1, p2)) = − 2⋅(1)/(2)⋅log2⎛⎝(p1)/(2) + (p2)/(2)⎞⎠ − 2⋅⎛⎝(p1)/(2) + (p2)/(2)⎞⎠((1)/(2))/(⎛⎝(p1)/(2) + (p2)/(2)⎞⎠) − 1 + λ = − log2⎛⎝(p1)/(2) + (p2)/(2)⎞⎠ − 2⋅(1)/(2) − 1 + λ = − log2⎛⎝(p1)/(2) + (p2)/(2)⎞⎠ − 2 + λ = 0
− log2⎛⎝(p1)/(2) + (p2)/(2)⎞⎠ = 2 − λ log2(2)/((p1 + p2)) = 2 − λ; (2)/((p1 + p2)) = 22 − λ; (p1 + p2) = (2)/(22 − λ); p1 + p2 = 2 − 1 + λ; p1 + p2 = 2 − 1 + λ; мора λ = 1 но тоа води кон:
I = − log(1)/(2) − 1 = 1 − 1 = 0
− p(x2)⋅[p(y1|x2)⋅log2(p(y1|x2) + p(y2|x2)⋅log2(p(y2|x2))] = − p1(αlog(α) + β⋅log2β) − p2((1 − α)log(1 − α) + (1 − β)log2(1 − β))
(9)
I
= − (αp1 + (1 − α)⋅p2)log2(αp1 + (1 − α)⋅p2) + (β⋅p1 + (1 − β)⋅p2)⋅log(β⋅p1 + (1 − β)⋅p2)
+ p1(αlog(α) + β⋅log2β) + p2((1 − α)log(1 − α) + (1 − β)log2(1 − β))
Ако α = β = 1 ⁄ 2
I = − 2⎛⎝(p1)/(2) + (p2)/(2)⎞⎠log2⎛⎝(p1)/(2) + (p2)/(2)⎞⎠ − p1 − p2
f(p1, p2) = − 2⎛⎝(p1)/(2) + (p2)/(2)⎞⎠log2⎛⎝(p1)/(2) + (p2)/(2)⎞⎠ − p1 − p2 + λ⋅∑2i = 1pi
(∂)/(∂p1)(f(p1, p2)) = − 2⋅(1)/(2)⋅log2⎛⎝(p1)/(2) + (p2)/(2)⎞⎠ − 2⋅⎛⎝(p1)/(2) + (p2)/(2)⎞⎠((1)/(2))/(⎛⎝(p1)/(2) + (p2)/(2)⎞⎠) − 1 + λ = − log2⎛⎝(p1)/(2) + (p2)/(2)⎞⎠ − 2⋅(1)/(2) − 1 + λ = − log2⎛⎝(p1)/(2) + (p2)/(2)⎞⎠ − 2 + λ = 0
− log2⎛⎝(p1)/(2) + (p2)/(2)⎞⎠ = 2 − λ log2(2)/((p1 + p2)) = 2 − λ; (2)/((p1 + p2)) = 22 − λ; (p1 + p2) = (2)/(22 − λ); p1 + p2 = 2 − 1 + λ; p1 + p2 = 2 − 1 + λ; мора λ = 1 но тоа води кон:
I = − log(1)/(2) − 1 = 1 − 1 = 0
Со решавање на 9↑ во Мапле се добива:
(2 α − 1)ln((1 − 2 x)α + x) + (2 β − 1)ln((1 − 2 x)β + x) − (1 − α)ln(1 − α) − (1 − β)ln(1 − β) − β ln(β) + 2 α − 2 + 2 β − α ln(α) = 0
(2 α − 1)ln((1 − 2 x)α + x) + (2 β − 1)ln((1 − 2 x)β + x) − H(α) − H(β) + 2(α + β − 1) = 0
log2(((1 − 2x)α + x)(2α − 1)((1 − 2 x)β + x)(2β − 1)) = − H(α) − H(β) + 2(α + β − 1)
(2 α − 1)ln((1 − 2 x)α + x) + (2 β − 1)ln((1 − 2 x)β + x) − H(α) − H(β) + 2(α + β − 1) = 0
log2(((1 − 2x)α + x)(2α − 1)((1 − 2 x)β + x)(2β − 1)) = − H(α) − H(β) + 2(α + β − 1)
\strikeout off\uuline off\uwave off(((1 − 2x)α + x)(2α − 1)((1 − 2 x)β + x)(2β − 1)) = 2 − H(α) − H(β) + 2(α + β − 1)
2α + 2 αln((1 − 2 x)α + x) + 2β + 2 βln((1 − 2 x)β + x) − ln((1 − 2 x)α + x) − ln((1 − 2 x)β + x) = H(α) + H(β) + 1
Решение од Ash Solutions (ги има во самиот Textbook)
Решение од Ash Solutions (ги има во самиот Textbook)
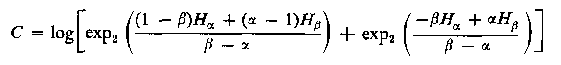
C = log2⎡⎣exp2⎛⎝((1 − β)Hα + (α − 1)Hβ)/(β − α)⎞⎠ + exp2⎛⎝( − βHα + αHβ)/(β − α)⎞⎠⎤⎦
α = 0 β = 1 ⁄ 2 ⇒
-Во Textbook-от од Ash се користи теоремата T3.3.3
α = 0 β = 1 ⁄ 2 ⇒
-Во Textbook-от од Ash се користи теоремата T3.3.3
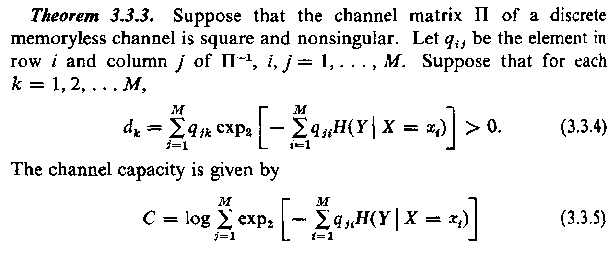
H(Y|X) = ∑2i = 1p(xi)⋅H(Y|xi) = p1⋅H(Y|p1) + p2⋅H(Y|p2) = − p(x1)⋅[p(y1|x1)⋅log2(p(y1|x1)) + p(y2|x1)⋅log2(p(y2|x1))]
− p(x2)⋅[p(y1|x2)⋅log2(p(y1|x2) + p(y2|x2)⋅log2(p(y2|x2))] = − p1(αlog(α) + β⋅log2β) − p2((1 − α)log(1 − α) + (1 − β)log2(1 − β))
H(Y|x1) = H(Y|p1) = − (p(y1|x1)⋅log2(p(y1|x1)) + p(y2|x1)⋅log2(p(y2|x1))) = αlog(α) + β⋅log2β
− p(x2)⋅[p(y1|x2)⋅log2(p(y1|x2) + p(y2|x2)⋅log2(p(y2|x2))] = − p1(αlog(α) + β⋅log2β) − p2((1 − α)log(1 − α) + (1 − β)log2(1 − β))
H(Y|x1) = H(Y|p1) = − (p(y1|x1)⋅log2(p(y1|x1)) + p(y2|x1)⋅log2(p(y2|x1))) = αlog(α) + β⋅log2β
\strikeout off\uuline off\uwave offH(Y|x2) = H(Y|p2) = − (p(y1|x2)⋅log2(p(y1|x2)) + p(y2|x2)⋅log2(p(y2|x2))) = (1 − α)log(1 − α) + (1 − β)⋅log2(1 − β)
⎡⎢⎣
p(y1)
p(y2)
⎤⎥⎦ = ⎡⎢⎣
α
1 − α
β
1 − β
⎤⎥⎦⎡⎢⎣
p(x1)
p(x2)
⎤⎥⎦
Π = ⎡⎢⎣
α
1 − α
β
1 − β
⎤⎥⎦ Π − 1 = (1)/(α − α⋅β − β + α⋅β)⎡⎢⎣
1 − β
α − 1
− β
α
⎤⎥⎦ = (1)/(α − β)⎡⎢⎣
1 − β
α − 1
− β
α
⎤⎥⎦ = ⎡⎢⎣
(1 − β)/(α − β)
(α − 1)/(α − β)
− (β)/(α − β)
(α)/(α − β)
⎤⎥⎦ = ⎡⎢⎣
q11
q12
q21
q22
⎤⎥⎦
\strikeout off\uuline off\uwave offC = log2⎡⎣exp2⎛⎝((1 − β)Hα + (α − 1)Hβ)/(β − α)⎞⎠ + exp2⎛⎝( − βHα + αHβ)/(β − α)⎞⎠⎤⎦
C = log{∑2j = 12 − ∑2i = 1qijH(Y|X = xi)} = log{2 − ∑2i = 1qi1H(Y|X = xi) + 2 − ∑2i = 1qi2H(Y|X = xi)} = log{2 − q11H(Y|X = x1) − q21H(Y|X = x2) + 2 − q12H(Y|X = x1) − q22H(Y|X = x2)} =
log{2 − q11(αlog(α) + β⋅log2β) − q21((1 − α)log(1 − α) + (1 − β)⋅log2(1 − β)) + 2 − q12((αlog(α) + β⋅log2β)) − q22((1 − α)log(1 − α) + (1 − β)⋅log2(1 − β)))} = log{2 − A + 2 − B}
A: = (1 − β)/(α − β)(αlog(α) + β⋅log2β) − (β)/(α − β)((1 − α)log(1 − α) + (1 − β)⋅log2(1 − β)) =
((1 − β)(αlog(α) + β⋅log2β) − β⋅((1 − α)log(1 − α) + (1 − β)⋅log2(1 − β)))/(α − β) =
log{2 − q11(αlog(α) + β⋅log2β) − q21((1 − α)log(1 − α) + (1 − β)⋅log2(1 − β)) + 2 − q12((αlog(α) + β⋅log2β)) − q22((1 − α)log(1 − α) + (1 − β)⋅log2(1 − β)))} = log{2 − A + 2 − B}
A: = (1 − β)/(α − β)(αlog(α) + β⋅log2β) − (β)/(α − β)((1 − α)log(1 − α) + (1 − β)⋅log2(1 − β)) =
((1 − β)(αlog(α) + β⋅log2β) − β⋅((1 − α)log(1 − α) + (1 − β)⋅log2(1 − β)))/(α − β) =
\strikeout off\uuline off\uwave off(1 − β)(αlog(α) + β⋅log2β) − β⋅((1 − α)log(1 − α) + (1 − β)⋅log2(1 − β)) = αlog(α) + β⋅log2β − βαlog(α) − β2⋅log2β − β(1 − α)log(1 − α) − β(1 − β)⋅log2(1 − β)
αlog(α) + β⋅log2β − βαlog(α) − β2⋅log2β − β(1 − α)log(1 − α) − β(1 − β)⋅log2(1 − β) = a(1 − b)log(a) − β(1 − α)log(1 − α) + b(1 − b)log(b) − β(1 − β)⋅log2(1 − β)
(1 − β)(αlog(α) + β⋅log2β) − β⋅((1 − α)log(1 − α) + (1 − β)⋅log2(1 − β))
B = (α − 1)/(α − β)((αlog(α) + β⋅log2β)) + (α)/(α − β)((1 − α)log(1 − α) + (1 − β)⋅log2(1 − β))) =
(α − 1)(αlog(α) + β⋅log2β) + α((1 − α)log(1 − α) + (1 − β)⋅log2(1 − β))) = (α − 1)αlog(α) + (α − 1)β⋅log2β + α(1 − α)log(1 − α) + α(1 − β)⋅log2(1 − β))
(α − 1)αlog(α) + (α − 1)β⋅log2β + α(1 − α)log(1 − α) + α(1 − β)⋅log2(1 − β))
-Гомнар сум дефиницијата на каналната матрица е како во Теорија на информации!!!!!!!!!!!!!!
Py = ⎡⎢⎢⎢⎣ p(Y1) p(Y2) p(Y3) ⎤⎥⎥⎥⎦; Π = ⎡⎢⎢⎢⎣ p11 p12 p13 p21 p22 p23 p31 p32 p33 ⎤⎥⎥⎥⎦; Px = ⎡⎢⎢⎢⎣ p(X1) p(X2) p(X3) ⎤⎥⎥⎥⎦; Py = ΠTPx; ⎡⎢⎢⎢⎣ p(Y1) p(Y2) p(Y3) ⎤⎥⎥⎥⎦ = ⎡⎢⎢⎢⎣ p11 p21 p31 p12 p22 p32 p13 p23 p33 ⎤⎥⎥⎥⎦⎡⎢⎢⎢⎣ p(X1) p(X2) p(X3) ⎤⎥⎥⎥⎦
(1 − β)(αlog(α) + β⋅log2β) − β⋅((1 − α)log(1 − α) + (1 − β)⋅log2(1 − β))
B = (α − 1)/(α − β)((αlog(α) + β⋅log2β)) + (α)/(α − β)((1 − α)log(1 − α) + (1 − β)⋅log2(1 − β))) =
(α − 1)(αlog(α) + β⋅log2β) + α((1 − α)log(1 − α) + (1 − β)⋅log2(1 − β))) = (α − 1)αlog(α) + (α − 1)β⋅log2β + α(1 − α)log(1 − α) + α(1 − β)⋅log2(1 − β))
(α − 1)αlog(α) + (α − 1)β⋅log2β + α(1 − α)log(1 − α) + α(1 − β)⋅log2(1 − β))
-Гомнар сум дефиницијата на каналната матрица е како во Теорија на информации!!!!!!!!!!!!!!
Py = ⎡⎢⎢⎢⎣ p(Y1) p(Y2) p(Y3) ⎤⎥⎥⎥⎦; Π = ⎡⎢⎢⎢⎣ p11 p12 p13 p21 p22 p23 p31 p32 p33 ⎤⎥⎥⎥⎦; Px = ⎡⎢⎢⎢⎣ p(X1) p(X2) p(X3) ⎤⎥⎥⎥⎦; Py = ΠTPx; ⎡⎢⎢⎢⎣ p(Y1) p(Y2) p(Y3) ⎤⎥⎥⎥⎦ = ⎡⎢⎢⎢⎣ p11 p21 p31 p12 p22 p32 p13 p23 p33 ⎤⎥⎥⎥⎦⎡⎢⎢⎢⎣ p(X1) p(X2) p(X3) ⎤⎥⎥⎥⎦
-Одам повторно со дефиницијата на канална матрица како во Теорија на информации
\mathchoice⎡⎢⎣
p(y1)
p(y2)
⎤⎥⎦ = ⎡⎢⎣
α1 − α
β1 − β
⎤⎥⎦T⎡⎢⎣
p(x1)
p(x2)
⎤⎥⎦ = ⎡⎢⎣
αβ
1 − α1 − β
⎤⎥⎦⎡⎢⎣
p(x1)
p(x2)
⎤⎥⎦ = ⎡⎢⎣
p(y1|x1)p(y1|x2)
p(y2|x1)p(y2|x2)
⎤⎥⎦⎡⎢⎣
p(x1)
p(x2)
⎤⎥⎦⎡⎢⎣
p(y1)
p(y2)
⎤⎥⎦ = ⎡⎢⎣
α1 − α
β1 − β
⎤⎥⎦T⎡⎢⎣
p(x1)
p(x2)
⎤⎥⎦ = ⎡⎢⎣
αβ
1 − α1 − β
⎤⎥⎦⎡⎢⎣
p(x1)
p(x2)
⎤⎥⎦ = ⎡⎢⎣
p(y1|x1)p(y1|x2)
p(y2|x1)p(y2|x2)
⎤⎥⎦⎡⎢⎣
p(x1)
p(x2)
⎤⎥⎦⎡⎢⎣
p(y1)
p(y2)
⎤⎥⎦ = ⎡⎢⎣
α1 − α
β1 − β
⎤⎥⎦T⎡⎢⎣
p(x1)
p(x2)
⎤⎥⎦ = ⎡⎢⎣
αβ
1 − α1 − β
⎤⎥⎦⎡⎢⎣
p(x1)
p(x2)
⎤⎥⎦ = ⎡⎢⎣
p(y1|x1)p(y1|x2)
p(y2|x1)p(y2|x2)
⎤⎥⎦⎡⎢⎣
p(x1)
p(x2)
⎤⎥⎦⎡⎢⎣
p(y1)
p(y2)
⎤⎥⎦ = ⎡⎢⎣
α1 − α
β1 − β
⎤⎥⎦T⎡⎢⎣
p(x1)
p(x2)
⎤⎥⎦ = ⎡⎢⎣
αβ
1 − α1 − β
⎤⎥⎦⎡⎢⎣
p(x1)
p(x2)
⎤⎥⎦ = ⎡⎢⎣
p(y1|x1)p(y1|x2)
p(y2|x1)p(y2|x2)
⎤⎥⎦⎡⎢⎣
p(x1)
p(x2)
⎤⎥⎦
Π = (1)/(α − α⋅β − β + α⋅β)⎡⎢⎣ 1 − β α − 1 − β α ⎤⎥⎦ = (1)/(α − β)⎡⎢⎣ 1 − β α − 1 − β α ⎤⎥⎦ = ⎡⎢⎣ (1 − β)/(α − β) (α − 1)/(α − β) − (β)/(α − β) (α)/(α − β) ⎤⎥⎦ = ⎡⎢⎣ q11 q21 q12 q22 ⎤⎥⎦
Види ги индексите на q. Намерно ги ставив така за да излезе резултатот како во книгата на Ash. Нема врска треба да бидат: ⎡⎢⎣ q11 q12 q21 q22 ⎤⎥⎦
Мислам дека сум го помешал j со i во формулата 3.3.5 од Ash.
H(Y|x1) = H(Y|p1) = − (p(y1|x1)⋅log2(p(y1|x1)) + p(y2|x1)⋅log2(p(y2|x1))) = − αlog(α) − (1 − α)⋅log2(1 − α) = H(α)
Π = (1)/(α − α⋅β − β + α⋅β)⎡⎢⎣ 1 − β α − 1 − β α ⎤⎥⎦ = (1)/(α − β)⎡⎢⎣ 1 − β α − 1 − β α ⎤⎥⎦ = ⎡⎢⎣ (1 − β)/(α − β) (α − 1)/(α − β) − (β)/(α − β) (α)/(α − β) ⎤⎥⎦ = ⎡⎢⎣ q11 q21 q12 q22 ⎤⎥⎦
Види ги индексите на q. Намерно ги ставив така за да излезе резултатот како во книгата на Ash. Нема врска треба да бидат: ⎡⎢⎣ q11 q12 q21 q22 ⎤⎥⎦
Мислам дека сум го помешал j со i во формулата 3.3.5 од Ash.
H(Y|x1) = H(Y|p1) = − (p(y1|x1)⋅log2(p(y1|x1)) + p(y2|x1)⋅log2(p(y2|x1))) = − αlog(α) − (1 − α)⋅log2(1 − α) = H(α)
\strikeout off\uuline off\uwave offH(Y|x2) = H(Y|p2) = − (p(y1|x2)⋅log2(p(y1|x2)) + p(y2|x2)⋅log2(p(y2|x2))) = − β⋅log(β) − (1 − β)⋅log2(1 − β) = H(β)
C = log{∑2j = 12 − ∑2i = 1qijH(Y|X = xi)} = log{2 − ∑2i = 1qi1H(Y|X = xi) + 2 − ∑2i = 1qi2H(Y|X = xi)} = log{2 − q11H(Y|X = x1) − q21H(Y|X = x2) + 2 − q12H(Y|X = x1) − q22H(Y|X = x2)} =
\strikeout off\uuline off\uwave offlog{2 − q11H(α) − q21H(β) + 2 − q12H(α) − q22H(β)} = log{2 − (1 − β)/(α − β)⋅H(α) − (a − 1)/(α − β)⋅H(β) + 2 + (β)/(α − β)⋅H(α) − (α)/(α − β)⋅H(β)} = log{2(1 − β)/(β − α)⋅H(α) + (a − 1)/(β − α)⋅H(β) + 2 − (β)/(β − α)⋅H(α) + (α)/(β − α)⋅H(β)} = log{2((1 − β)H(α) + (a − 1)H(β))/(β − α) + 2( − β⋅H(α) + αH(β))/(β − α)}
\mathchoiceC = log2⎡⎣exp2⎛⎝((1 − β)Hα + (α − 1)Hβ)/(β − α)⎞⎠ + exp2⎛⎝( − βHα + αHβ)/(β − α)⎞⎠⎤⎦C = log2⎡⎣exp2⎛⎝((1 − β)Hα + (α − 1)Hβ)/(β − α)⎞⎠ + exp2⎛⎝( − βHα + αHβ)/(β − α)⎞⎠⎤⎦C = log2⎡⎣exp2⎛⎝((1 − β)Hα + (α − 1)Hβ)/(β − α)⎞⎠ + exp2⎛⎝( − βHα + αHβ)/(β − α)⎞⎠⎤⎦C = log2⎡⎣exp2⎛⎝((1 − β)Hα + (α − 1)Hβ)/(β − α)⎞⎠ + exp2⎛⎝( − βHα + αHβ)/(β − α)⎞⎠⎤⎦ Ова е уште поопшта форма од онаа во Cover 2C = 2C1 + 2C2
α = 0 β = 1 ⁄ 2 ⇒
Π = ⎡⎢⎣ α 1 − α β 1 − β ⎤⎥⎦ = ⎡⎢⎣ 0 1 0.5 0.5 ⎤⎥⎦
C = log2⎡⎣exp2⎛⎝( − Hβ)/(0.5)⎞⎠ + exp2⎛⎝(0)/(β − α)⎞⎠⎤⎦ = log2[exp2( − 2) + 1] = log2⎡⎣(1)/(4) + 1⎤⎦ = log2⎡⎣(5)/(4)⎤⎦ = log2(5) − 2⋅log2(2) = 0.32
\mathchoiceC(0, (1)/(2)) = (ln(5) − 2 ln(2))/(ln(2)) = 0.32C(0, (1)/(2)) = (ln(5) − 2 ln(2))/(ln(2)) = 0.32C(0, (1)/(2)) = (ln(5) − 2 ln(2))/(ln(2)) = 0.32C(0, (1)/(2)) = (ln(5) − 2 ln(2))/(ln(2)) = 0.32
-Сегам сакам да проверам дали истото важи и за за 3x2 матрицата од чланакот
y3|x1 a b 0 1 0 1 0.5 0.5 2 0.5 0.5
Нема шанси. Aко матрицата не е квадратна не можеш да пресметаш инверзна матрица.
α = 0 β = 1 ⁄ 2 ⇒
Π = ⎡⎢⎣ α 1 − α β 1 − β ⎤⎥⎦ = ⎡⎢⎣ 0 1 0.5 0.5 ⎤⎥⎦
C = log2⎡⎣exp2⎛⎝( − Hβ)/(0.5)⎞⎠ + exp2⎛⎝(0)/(β − α)⎞⎠⎤⎦ = log2[exp2( − 2) + 1] = log2⎡⎣(1)/(4) + 1⎤⎦ = log2⎡⎣(5)/(4)⎤⎦ = log2(5) − 2⋅log2(2) = 0.32
\mathchoiceC(0, (1)/(2)) = (ln(5) − 2 ln(2))/(ln(2)) = 0.32C(0, (1)/(2)) = (ln(5) − 2 ln(2))/(ln(2)) = 0.32C(0, (1)/(2)) = (ln(5) − 2 ln(2))/(ln(2)) = 0.32C(0, (1)/(2)) = (ln(5) − 2 ln(2))/(ln(2)) = 0.32
-Сегам сакам да проверам дали истото важи и за за 3x2 матрицата од чланакот
y3|x1 a b 0 1 0 1 0.5 0.5 2 0.5 0.5
Нема шанси. Aко матрицата не е квадратна не можеш да пресметаш инверзна матрица.
-Продолжувам со чланакот на страна 127. Да видам каква е каналната матрица ако x2 = 0
(11)
y3|x1
a
b
0
1 ⁄ 2
1 ⁄ 2
1
1 ⁄ 2
1 ⁄ 2
2
1 ⁄ 2
1 ⁄ 2
In both cases the channel matrix has a capacity equal to 0.32 ([1], page 85, problem 3.7). If x2 is held to zero, all input letters x1 appear completely noisy at terminal 3. Ова е логично и следи директно од 11↑. (За било кој влезен симбол y3 подеднакво е веројатно да биде а т.е b. Со тоа неговата вредност е целосно неизвесна знаејќи ги влезните симболи. Затоа вели дека сите влезни симболи x1 се појавуваат целосно ошумени во терминалот 3). Thus C1(1, 3) = 0.32. (Мене ова не ми изгледа логично да важи за кејсот x2 = 0 . Ваква вредност се добиваат само ако за еден влезен симбол еден излезен е со веројатност 1, а за другиот влезен изезот е пата-пата. Види го решението 10↑). Ова што го користат согласно проблемот 3.7 од Ash ми изгледа сосема логично. Имено користат само два кодни знака за кодирање на кодните зборови т.е W ∈ {1, ..M} = {1, ..2nR} = {1, ...21⋅1} = {1, 2}. Ако користиш три кодни знака ќе треба добиениот капацитет да го делиш со log2(M).
-Да видам што се добива ако во 1↑ земам x2 = 1 i.e x2 = 2 :
y3|x1
a
b
0
1
0
1
1 ⁄ 2
1 ⁄ 2
2
1 ⁄ 2
1 ⁄ 2
y3|x1
a
b
0
0
1
1
1 ⁄ 2
1 ⁄ 2
2
1 ⁄ 2
1 ⁄ 2
In other words, if terminal 2 keeps his input x2 fixed at 1 or 2 there exist a code for sending in the 1-3 direction at rate arbitrarily close to 0.32. (Ова би рекол дека е точно само ако се пренесуваат симболите 0 и 1 или 0 и 2. Aко одиш со три симболи немаш квадратна матрица и нема да можеш да ја користиш Theorem 3.3.3 од Ash која користи инверзна канална матрица за пресметка на капацитетот.)
There is still another way of transmitting information over the channel which enables terminal 1 to send to terminal 3 at a rate up to 0.5. This may be seen as follows. If x2 is held at zero it is possible to transmit in the 1-2 direction at rate one. In that case the letters 1 and 2 transmitted at terminal 1 result with certainty in a an b respectively at terminal 2.
-Да го добијам ова со користење на Табела I:
y2|x1 a b 0 1 ⁄ 2 1 ⁄ 2 1 1 0 2 0 1
Апсолутно е точно тврдењето во црвено!!!
29.06.2014
во табелата горе е дадена условна веројатност!!!!
H(Y2|X1) = p(X1 = 1)H(Y2|X1 = 1) + p(X1 = 2)H(Y2|X1 = 2) = 0
I(X1;Y2) = H(Y2) − 0 = H⎛⎝(1)/(2)⎞⎠ = 1
пази!!! 0-та пошто е целсно ошумена не ја земам во предвид при пресметка на H(Y2).
y2|x1 a b 0 1 ⁄ 2 1 ⁄ 2 1 1 0 2 0 1
Апсолутно е точно тврдењето во црвено!!!
29.06.2014
во табелата горе е дадена условна веројатност!!!!
H(Y2|X1) = p(X1 = 1)H(Y2|X1 = 1) + p(X1 = 2)H(Y2|X1 = 2) = 0
I(X1;Y2) = H(Y2) − 0 = H⎛⎝(1)/(2)⎞⎠ = 1
пази!!! 0-та пошто е целсно ошумена не ја земам во предвид при пресметка на H(Y2).
Otherwise if we held x2 at 1 or 2 the x1 letters appear completely noisy at terminal 2.
y2|x1
a
b
0
1 ⁄ 2
1 ⁄ 2
1
1 ⁄ 2
1 ⁄ 2
2
1 ⁄ 2
1 ⁄ 2
y2|x1
a
b
0
1 ⁄ 2
1 ⁄ 2
1
1 ⁄ 2
1 ⁄ 2
2
1 ⁄ 2
1 ⁄ 2
Similarly if x1 is held at zero it is possible to send one bit per second in the 2-3 direction by using only the letters 1 and 2 at terminal 2 which then result with certainty in a and b respectively at terminal 3.
y3|x2
a
b
0
1 ⁄ 2
1 ⁄ 2
1
1
0
2
0
1
Otherwise all x2 letters appear completely noisy at terminal 3. It is therefore possible to send one bit per second in both directions, however not simultaneously.
Let now, the three teminals adopt the following strategy. First x2is held at 0 and terminal 1 sends information to terminal 2 at rate one. Then x1 is held at 0 and terminal 2 sends the received information on to terminal 3, also at rate one. By dividing the time for use of these two strategies in the ratio λ to 1 − λ , it is possible to transmit in the 1-3 direction at a rate equal to the smallest of the two numbers λ and 1 − λ, that is, at a rate up to 0.5. We summarize the rezult in 6↓. It will follow from later results that it is not possible to transmit in 1-3 direction at rate higher than 0.5 with arbitrary small proability of error.
In the previous examples we have seen how terminal 1 can achieve a transmission rate different from C1(1, 3) by first sending information to terminal 2 who then sends the received information on to terminal 3. Suppose now that both C1(1, 2) and C1(1, 3) are equal to zero. In this case terminal 1 cannot influence either the otuputs at terminal 2 or the outputs at terminal 3 in one single channel operation, and the two different methods indicated in example 3 for sending in the 1-3 direction both fail. As we shall see there may still exist a method to send information at a positive rate from terminal 1 to terminal 3. Suppose all input and output letters in this example are binary. Let the probabilities P(y2, y3|x1, x2|x3) of different output pairs (y2, y3) conditional on various input pairs (x1, x2), for arbitrary x3 , be given in 3↓.
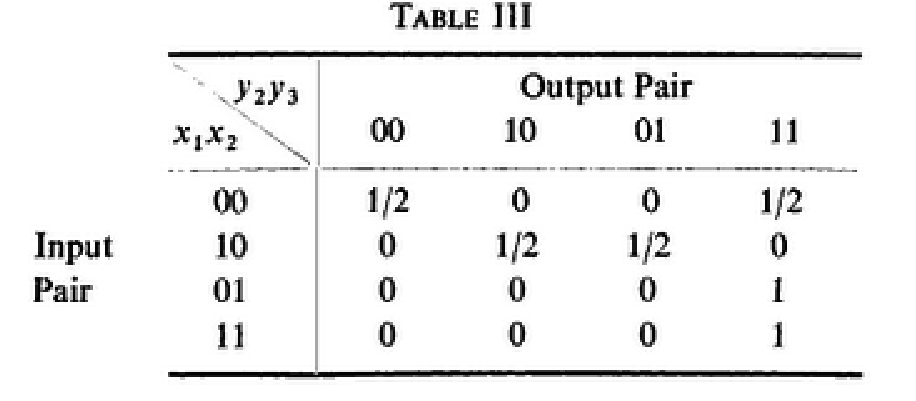
No matter which letter terminal 2 transmits (either 0 or 1) all input letters x1 appear completely noisy at both terminal 2 and terminal 3. Thus \mathchoiceC1(1, 2) = C1(1, 3) = 0C1(1, 2) = C1(1, 3) = 0C1(1, 2) = C1(1, 3) = 0C1(1, 2) = C1(1, 3) = 0.
One might expect that no communication is possible from terminal 1 to terminal 3 at all. Surprisingly enough, however, it will turn out that one can transmit over this channel in the 1-3 direction at rate of 0.24.
Suppose x2 is held at zero. The conditional probabilities P(y2, y3|x1|x2) as x2 = 0 are given by the first two rows of 3↑. Together these two rows form a loss-less channel for sending from terminal 1 to pair of terminals (2, 3). That is C1[1, (2, 3)] = 1. If the receiver at terminal 3 could see both outputs y2 and y3 received over this loss-less channel he would be able to specify the transmitted x1 uniquely.
If the observed y2 and y3 are the same, he knows x1 = 0 was sent. If y2 and y3 are different he knows x1 = 1 was sent. Terminal 3 could learn about the output letter y2 if terminal 2 sends information about this letter over the channel after he has observed it himself. If x1 = 0 the corresponding channel p(y3|x2|x1) for sending from terminal 2 to terminal 3 has capacity equal to 0.32. This method clearly provides a rule for the three terminal for sending in two channel operations information from terminal 1 to terminal 3. By deviding the time for use of these two strategies in the right proportion it is possible to transmit in the 1-3 direction at rate up to:
\mathchoiceC = (0.32)/(1 + 0.32) = 0.242424C = (0.32)/(1 + 0.32) = 0.242424C = (0.32)/(1 + 0.32) = 0.242424C = (0.32)/(1 + 0.32) = 0.242424 Не знам од каде доаѓа ова!!!(изгледа од формулите во глава 7)
Изгледа ова е согласно 44↓.
\strikeout off\uuline off\uwave offR3 = (C1[1, (2, 3)]⋅C1(2, 3))/(C1(2, 3) + logb2)
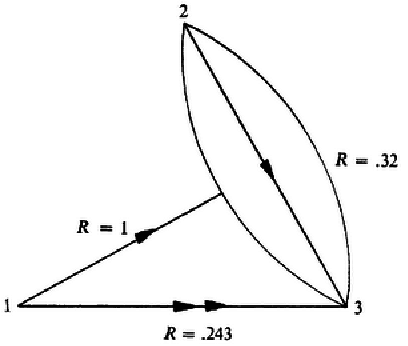
Schematically we have represented these results in 6↑.
Here is another simple example which shows yet another way of sending information from terminal 1 to terminal 3. The method to be describet here is better, for this particular channel, than any of the methods described in the foregoing examples. Suppose for this channl all inputs and output letters are again binary. Let the probabilities P(y2, y3|x1, x2|x3) of different output pairs (x1, x2) be the same for different x3 and be given by 4↓.
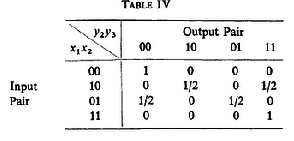
Let us first compare for this example the various methods of transmission described in the previous examples. It is not hard to see that for this example C1(1, 3) = C1(2, 3) = 0, 32 (логично е зошто и во давата случаи ако го држиш другиот симбол фиксен y3 е фиксиран за едната излезна вредност за еден влезен симбол со веројатнос 1, а за другиот со пата-пата веројатност меѓу двете излезни вредности). We observe that, regardless of which letter terminal 2 puts in, the letters 0 and 1 transmitted at terminal 1 result with certainty into 0 and 1 respectively at terminal 2. Therefore C1(1, 2) = 1 and also C1[1, (2, 3)] = 1 (Второво важи за било која вредност на x2). Thus if terminal 1 first sends information at rate one to terminal 2, who then sends the received information on to terminal 3 at rate 0.32, transmission in the 1-3 direction is possible at rate equal to:
\mathchoiceC = (0.32)/(1 + 0.32) = 0.242424C = (0.32)/(1 + 0.32) = 0.242424C = (0.32)/(1 + 0.32) = 0.242424C = (0.32)/(1 + 0.32) = 0.242424
Similarly if terminal 1 sends information to the pair of terminals (2,3) at rate one, and terminal 2 sens information about the received letter sequence to terminal 3 at rate o.32, it is posible to transmit in 1-3 direction at rate 0.243. Thus, using any of the methods described so far, the highest rate taht can be attained is 0.32.
We now propose a forth method which in this particular example will enable terminal 1 to transmit to terminal 3 at a rate arbitrarily close to \mathchoice0.50.50.50.5.
The conditional probabilities P(y3|x1, x2) are given by
y3|x1, x2
0
1
00
1
0
10
1 ⁄ 2
1 ⁄ 2
01
1 ⁄ 2
1 ⁄ 2
11
0
1
The capacity of this channel matrix is clearly equal to one and is achieved by using only the input pairs (0, 0) and (1,1). Thus \mathchoiceC1[(1, 2)3] = 1C1[(1, 2)3] = 1C1[(1, 2)3] = 1C1[(1, 2)3] = 1.
Suppose a person could operate the inputs at both terminal 1 and 2 simultaneously. In sending to terminal 3 he would make use only of the input pairs (0,0) and (1,1). These pairs are received as 0 and 1 respectively at terminal 3. Now terminal 1 can in fact control the inputs at terminal 1 and 2 as follows.
He may first send a letter to terminal 2 over the noiseless channel P(y2|x1|x2) instructing terminal 2 which letter to send durin the next period. (каналот x1 → y2 e безшумен зошто ако пратиш x1 = 0 (без оглед на x2) со сигруност добиваш y2 = 0 и обратно ако пратиш x1 = 1 (без оглед на x2) со сигруност добиваш y2 = 1). At the next input terminal 2 sends the letter terminal 1 has instructed him to send, and terminal 1 himself also puts in a letter to the channel. This pair together is then transmitted to terminal 3. In the decoding procedure terminla 3 only pays attention on the second letter received. In this particular example suppose terminal 1 wants to send a 0 to terminal 3. He then first puts in a 0 which is received as 0 at terminal 2. At the next period both terminal 1 and terminal 2 put in a 0, which pair is then received with certainty as 0 at termina 3 and decoded correctly there as 0. By deviding the time for use of these two strategies into equal periods it is possible here to transmit in the 1-3 direction at a rate equal to 0.5
Претпоставувам дека се добива од (1)/(1 + 1) = 0.5
. Thus the forth method yields a result which, for this particular example, is better than the rates provided by the previous methods. The result is summarized in 8↓.
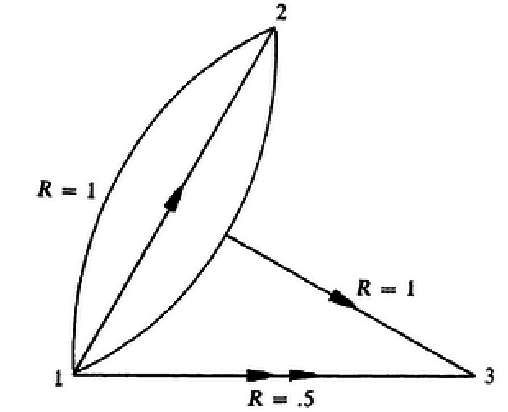
It is shown in Section 10 that it is not possible to transmit in the 1-3 direction at rate higher than 0.5 with arbitrarily small probability of error.
4 Basic inequality for single-letter capacities
In Section 2 we introduced the capacities C1(1, 2), C1(1, 3), C1(2, 3), C1[1, (2, 3)] and C1[(1, 2), 3] in order to illustrate the different ways of transmission through the channel. In this section we give precise definitions of these capacities. They are called single-letter capacities since they correspond to one single channel operation and involve a maximizing process over single input letters to the channel only. The single-letter capacities satisfy a number of inequalities similar to the properties of average mutual inforamtion functions which are standard in information theory.
Let a d.m three terminal channel P(y1y2y3|x1x2x3) be given. For fixed inputs x2 and x3 and a probability distribution P(x1) on input x1 there is a corresponding probability distribution on the set A1x B2x B3 of triples (x1, y2, y3) defined by:
(12) P(x1, y2, y3|x2x3) = ⎲⎳y1P(y1, y2, y3|x1, x2, x3).P(x1)
Let
(13)
1R[1, (2, 3)|P(x1);x2, x3]
= E⎡⎣log⎛⎝(P(x1, y2, y3|x2, x3))/(P(x1)P(y2, y3|x2x3))⎞⎠⎤⎦
Логично е вака што го пишува на левата страна зата што во генерален случај треба во именителот да иамаш P(x1|x2x3) но x1 не зависи од x2 и x3 па затоа имаш само P(x1) .
where the expected value is taken with respect to the distribution 12↑.
I(X;Y) = H(Y) − H(Y|X); I(X;Y) = ⎲⎳x, yp(x, y)⋅log2⎛⎝(p(x, y))/(p(x)⋅p(y))⎞⎠ = ⎲⎳x, yp(x, y)⋅log2⎛⎝(1)/(p(x))⎞⎠ + ⎲⎳x, yp(x, y)⋅log2⎛⎝(p(x, y))/(p(y))⎞⎠
⎲⎳x, yp(x, y)⋅log2⎛⎝(1)/(p(x))⎞⎠ + ⎲⎳x, yp(x, y)⋅log2⎛⎝(p(x, y))/(p(y))⎞⎠ = ⎲⎳xp(x)⋅log2⎛⎝(1)/(p(x))⎞⎠ + ⎲⎳x, yp(x, y)⋅log2(p(x|y))
= ⎲⎳x, yp(x, y)⋅log2⎛⎝(1)/(p(x))⎞⎠ − ⎲⎳x, yp(x, y)⋅log2(1)/((p(x|y))) = H(x) − H(X|Y)
(Значи P(y2, y3|x2x3) одговара на p(y) од подвлечениот дел од изразот погоре.)
R(1, (2, 3)|P(x1);x2, x3) = I(X1;Y2Y3|x2x3)
(Ги пишувам x2x3 со мали букви зошто не одам по сите нивни вредности туку за една нивна фиксна вредност. Означувањето што го користат во чланаков мислам дека е слично. Со малите вредности на x2 и x3 сака да каже дека се фиксни вредности, а со P(x1) сака да каже дека се работи за сите вредности на x1).
We may write 13↑ also as:
(14) \mathchoiceR[1, (2, 3)|P(x1);x2x3]R[1, (2, 3)|P(x1);x2x3]R[1, (2, 3)|P(x1);x2x3]R[1, (2, 3)|P(x1);x2x3] = H(X1) − H(X1|Y2Y3, x2x3)
(Тука мојот резон се изедначува со оној во чланакот).
That is uncertainty of x1 , less the uncertainty in x1 given y2 and y3 on the average, with respect to P(x1, y2, y3|x2x3). Define
C1[1, (2, 3)] = maxx2, x3maxp(x1)[1, (2, 3)|P(x1);x2x3]
Овде мислам деака сака да каже дека го пресметува вториот max за различни вредности на (x2, x3) и потоа пара супремум од добиените максимуми.
Similarly let:
and
R[1, 3|P(x1);x2x3] = H(X1) − H(X1|Y3, x2x3) = E⎡⎣log⎛⎝(P(x1, y3|x2, x3))/(P(x1)P(y3|x2x3))⎞⎠⎤⎦
where both expectations are taken with respect to distribution12↑. Define
C1[1, 2] = maxx2, x3maxp(x1)R[1, 2|P(x1);x2x3]
C1[1, 3] = maxx2, x3maxp(x1)R[1, 3|P(x1);x2x3]
Now let the inputs x1, x3 be fixed and suppose a probability distribution P(x2) is given on inputs x2. Then
(16) P(x2, y3|x1x3) = ⎲⎳y1, y2P(y1, y2, y3|x1, x2, x3).P(x2)
determines a probability distribution on pairs (x2, y3). Let
where the expected value is taken with respect to the distribution 16↑. Define
(18) C1[2, 3] = maxx1, x3maxp(x2)R[2, 3|P(x2);x1x3]
Finaly let the input x3 be fixed and suppose P(x1, x2) is given probability distributon on pairs of inputs (x1, x2). Then
(19) P(x1x2, y3|x3) = ⎲⎳y1y2P(y1, y2, y3|x1x2, x3)⋅P(x1x2)
determines a probability distribution on triples (x1, x2, x3). Let
\mathchoiceR[(1, 2), 3|P(x1x2); x3]R[(1, 2), 3|P(x1x2); x3]R[(1, 2), 3|P(x1x2); x3]R[(1, 2), 3|P(x1x2); x3] = H(X1X2) − H(X1X2|Y3, x3) = E⎡⎣log⎛⎝(P(x1, x2, y3|x3))/(P(x1x2)P(y3|x3))⎞⎠⎤⎦
where expected value is taken with respect to 19↑. Define:
C1[(1, 2), 3] = maxx3maxP(x1, x2)R[(1, 2), 3|P(x1x2); x3]
We now state and prove a number of inequalities satisfied by the various single-letter capacities just defined. These inequalities are basic to understand the underlying ideas and are being used throughout.
C1(1, 3) ≤ C1[1, (2, 3)] with equality if both
P(y2, y3|x1x2x3) = P(y2|x1, x2, x3)P(y3|x1, x2, x3)
(i.e., the outputs y2 and y3 are conditionaly independent given the inputs x1x2 and x3), and \mathchoiceC1(1, 2) = 0C1(1, 2) = 0C1(1, 2) = 0C1(1, 2) = 0.
Дискусија
\strikeout off\uuline off\uwave offR[1, 2|P(x1);x2x3] = H(X1) − H(X1|Y2, x2x3) = E⎡⎣log⎛⎝(P(x1, y2|x2, x3))/(P(x1)P(y2|x2x3))⎞⎠⎤⎦ C1[1, 2] = maxx2, x3maxp(x1)R[1, 2|P(x1);x2x3]
(Маливе букви значат фиксни вредности а не случајни променливи па затоа не ги земам во предвид во chain rule.)
\strikeout off\uuline off\uwave offR[1, (2, 3)|P(x1);x2x3] = H(X1) − H(X1|Y2Y3, x2x3) = H(Y2Y3) − H(Y2Y3|X1, x2, x3) = H(Y2Y3) − H(Y2|X1, x2, x3) − H(Y3|X1, x2, x3)
|R[1, 2|P(x1);x2x3] = H(X1) − H(X1|Y2, x2x3) = H(Y2) − H(Y2|X1, x2x3) = 0 ⇒ X1and Y2 are independent.|
⇒ \mathchoiceR[1, (2, 3)|P(x1);x2x3]R[1, (2, 3)|P(x1);x2x3]R[1, (2, 3)|P(x1);x2x3]R[1, (2, 3)|P(x1);x2x3] = H(Y2Y3) − H(Y2) − H(Y3|X1, x2, x3) = H(Y2) + H(Y3|Y2) − H(Y2) − H(Y3|X1, x2, x3) = H(Y3|Y2) − H(Y3|X1, x2, x3)
= H(Y3|Y2) − H(Y3|Y2, X1, x2, x3) = I(X1;Y3|Y2, x2, x3) = H(X1|Y2, x2, x3) − H(X1|Y2, Y3, x2, x3) = H(X1|x2, x3) − H(X1|Y3, x2, x3)
= I(X1;Y3) = \mathchoiceC1[1, 3]C1[1, 3]C1[1, 3]C1[1, 3]
Lema 4.2
C1(1, 2) ≤ C1[1, (2, 3)] with equality if both
P(y2, y3|x1x2x3) = P(y2|x1, x2, x3)⋅P(y3|x1x2x3)
and C1(1, 3) = 0
Proof:
C1(1, 3) = 0 ⇒ I(X1;Y3) = H(X1) − H(X1|Y3) = 0 ⇒ H(X1|Y3) = H(X1) ⇒ X1 andY3 are independendt.
\mathchoiceR[1, (2, 3)|P(x1);x2x3]R[1, (2, 3)|P(x1);x2x3]R[1, (2, 3)|P(x1);x2x3]R[1, (2, 3)|P(x1);x2x3] = H(Y2Y3) − H(Y2|X1, x2, x3) − H(Y3|X1, x2, x3) = \cancelH(Y3) + H(Y2|Y3) − H(Y2|X1, x2, x3) − \cancelH(Y3)
\overset(a) = H(Y2|Y3) − H(Y2|X1, Y3 x2, x3) = I(X1;Y2|Y3) = H(X1|Y3) − H(X1|Y2Y3) = H(X1) − H(X1|Y2) = \mathchoiceI(X1;Y2)I(X1;Y2)I(X1;Y2)I(X1;Y2)
(a)-since Y2 and Y3 are independent given X1, x2, x3
\strikeout off\uuline off\uwave offIf C1[1, (2, 3)] = 0 then C1(1, 2) = C1(1, 3) = 0
C1(1, 3) ≤ C1[(1, 2), 3] with equality \mathchoiceC1(2, 3) = 0C1(2, 3) = 0C1(2, 3) = 0C1(2, 3) = 0
Proof:
C1(2, 3) = 0 ⇒ X2 and Y3 are independent. of
Овде претпоставувам дека:
P(x1, x2|y3x3) = P(x1|y3, x3)⋅P(x2|Y3, x3)
\mathchoiceR[(12), 3|P(x1);x2x3]R[(12), 3|P(x1);x2x3]R[(12), 3|P(x1);x2x3]R[(12), 3|P(x1);x2x3] = H(X1X2) − H(X1X2|Y3, x2, x3) = H(X2) + H(X1|X2) − H(X1|Y3, x2, x3) − H(X2|Y3, X1 x2, x3)
= \cancelH(X2) + H(X1|X2) − H(X1|Y3, x2, x3) − \cancelH(Y2) = H(X1|X2) − H(X1|X2, Y3, x2, x3) = I(X1;Y3|X2) = H(Y3|X2) − H(Y3|X1X2) =
\strikeout off\uuline off\uwave off = H(Y3) − H(Y3|X1) = \mathchoiceI(X1;Y3)I(X1;Y3)I(X1;Y3)I(X1;Y3)
(a)-since X1 and X2 are independent given Y3
C1(2, 3) ≤ C1[(1, 2), 3] with equality \mathchoiceC1(1, 3) = 0C1(1, 3) = 0C1(1, 3) = 0C1(1, 3) = 0
C1[(1, 2), 3] = 0 if and only if C1(1, 3) = C1(2, 3) = 0
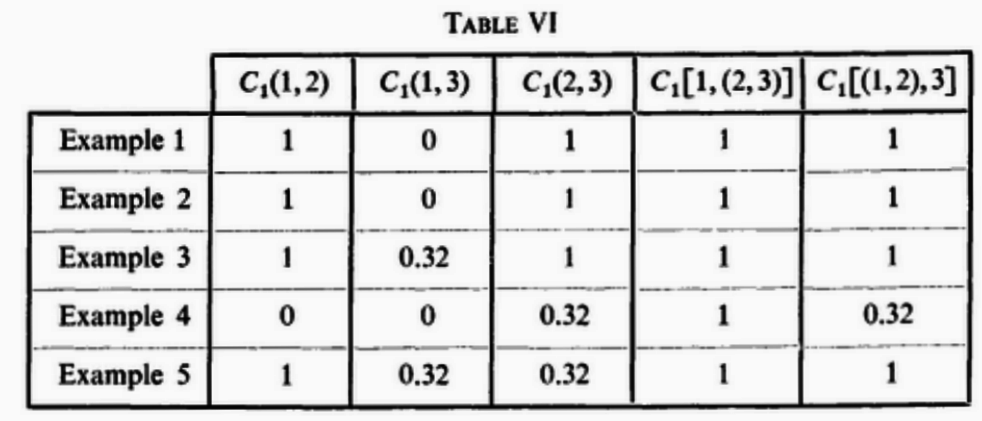
Remark. In 5↑ we have evaluated for each example of Section 3 the single-letter capacities C1(1, 2), C1(1, 3), C1(2, 3), C1(1, (2, 3)) and C1[(1, 2), 3].
In Example 4 one has C1(1, 2) = C1(1, 3) = 0 (ова на прв поглед важи само за x2 = 0 но подолу го изведов и за x2 = 1) but C1[1, (2, 3)] = 1. Thus the converse of corollary 4.1 is not necessarily true. The converse holds only if:
P(y2, y3|x1x2x3) = P(y2|x1, x2, x3)⋅P(y3|x1x2x3)
Да, затоа што во тој случај Лемата 4.2 е со еднаквост т.е. 0 = C1(1, 2) = C1[1, (2, 3)]
maxp(x)I(X;Y) = H(X) − H(X|Y) = log2(2) − 1\overset(a) = 0 I(X;Y) = H(Y) − H(Y|X)\overset(b) = 1log(1) − 0
(a) Кога ќе го примиш Y имаш максимална неизвесност. Можеби е пратена 0 а можеби 1.
(b) Не посоти неизвесност. Ако пратиш x = 0 → y = 1, ако праитиш x = 1 пак y = 1.
(a) Кога ќе го примиш Y имаш максимална неизвесност. Можеби е пратена 0 а можеби 1.
(b) Не посоти неизвесност. Ако пратиш x = 0 → y = 1, ако праитиш x = 1 пак y = 1.
it clearly sufices to prove only Lemmas 4.1 and 4.3
Let x2 and x3 be fixed and let P(x1) be a given probability distribution on inputs x1. It follows form Feinstein ([3], page 16, Lemma 6) that
R(1, 3|P(x1);x2, x3) ≤ R[1, (2, 3)|P(x1);x2, x3]
I(X1;Y3|X1) = ?
I(X1;Y2, Y3|X1) = I(X1;Y3|X1) + I(X1;Y2|Y3X1) ⇒ I(X1;Y2, Y3|X1) ≥ I(X1;Y3|X1)
Чудна работе е што вториот член ми изгледа дека треба да биде 0 без никакви предуслови. H(X1|X1)=0!?
- Now assume P(y2, y3|x1, x2, x3) = P(y2|x1, x2, x3)⋅P(y3|x1x2x3) for all x1, x2, x3, y2 and y3 and suppose C1(1, 2) = 0. The last assumption means that for all x2, x3, y2 fixed P(y2|x1x2x3) remains the same as x1 varies (Ова е логично зошто y2 не зависи од x1 заради C1(1, 2) = 0. Јас би рекол дека уште и дека) ([7] page 17). Thus
(20) P(y2, y3|x2, x3) = ⎲⎳x1P(x1)P(y2|x1x2x3)P(y3|x1x2x3) = \mathchoiceP(y2|x1, x2, x3)P(y2|x1, x2, x3)P(y2|x1, x2, x3)P(y2|x1, x2, x3)P(y3|x2, x3)
for all y2, y3 and x1.
RHS = P(y2, y3|x2, x3) = P(y2|x2, x3)⋅P(y3|x2, x3). Aма со оглед на тоа што x1 и y2 се статистички независни следи дека: P(y2|x2, x3) = \mathchoiceP(y2|x1, x2, x3)P(y2|x1, x2, x3)P(y2|x1, x2, x3)P(y2|x1, x2, x3)
It follows that
(21) P(y2, y3|x1, x2, x3)⋅P(y3|x2, x3) = P(y2, y3|x2, x3)⋅P(y3|x1, x2, x3)
Иницијален обид за да го докажам како се доаѓа до 22↓
Proof
P(y2y3|x2x3) = P(y2|x1, x2, x3)P(y3|x2, x3) ⇒ P(y3|x2, x3) = (P(y2y3|x2x3))/(P(y2|x1, x2, x3)) (*) ⇒ P(y2, y3|x1, x2, x3) = P(y2|x1, x2, x3)⋅P(y3|x1x2x3)\overset(a) ⇒
P(y2, y3|x1, x2, x3)⋅P(y3|x2, x3) = \cancelP(y2|x1, x2, x3)⋅P(y3|x1x2x3)⋅(P(y2y3|x2x3))/(\cancelP(y2|x1, x2, x3)) = P(y3|x1x2x3)⋅P(y2y3|x2x3)
(a) - Множам лево и десно со (*)
P(y2, y3|x1, x2, x3)⋅P(y3|x2, x3) = \cancelP(y2|x1, x2, x3)⋅P(y3|x1x2x3)⋅(P(y2y3|x2x3))/(\cancelP(y2|x1, x2, x3)) = P(y3|x1x2x3)⋅P(y2y3|x2x3)
(a) - Множам лево и десно со (*)
Уште еден обид
P(y2, y3|x1, x2, x3)⋅P(y3|x2, x3) = P(y2, y3|x2, x3)⋅P(y3|x1, x2, x3); P(y2|x1, x2, x3)⋅\cancelP(y3|x1, x2, x3)⋅P(y3|x2, x3) = P(y2, y3|x2, x3)⋅\cancelP(y3|x1, x2, x3);
P(y2|x1, x2, x3)⋅P(y3|x2, x3) = P(y2, y3|x2, x3);
P(y2|x1, x2, x3)⋅P(y3|x2, x3) = P(y2, y3|x2, x3);
\strikeout off\uuline off\uwave offP(y2, y3|x2, x3) = P(y2|x2, x3)⋅P(y3|y2, x2, x3) = P(y3|x2, x3)⋅P(y2|y3, x2, x3)
P(y2|x1, x2, x3)⋅\cancelP(y3|x2, x3) = \cancelP(y3|x2, x3)P(y2|y3, x2, x3); ⇒ P(y2|x1, x2, x3) = P(y2|y3, x2, x3)
P(x1, y2|y3, x2, x3) = P(y2|y3, x2, x3)⋅P(x1|y2, y3, x2, x3) = P(y2|x1, x2, x3)⋅P(x1|y2, y3, x2, x3)
P(x1, y2|y3, x2, x3) = P(y2|y3, x2, x3)⋅P(x1|y2, y3, x2, x3) = P(y2|x1, x2, x3)⋅P(x1|y2, y3, x2, x3)
or alternatively
(22) P(x1, y2|y3, x2, x3) = P(x1|y3x2x3)⋅P(y2|y3, x2, x3)
\strikeout off\uuline off\uwave offP(y2, y3|x1, x2, x3) = P(y2|x1, x2, x3)⋅P(y3|x1, x2, x3) = P(y2|x2, x3)⋅P(y3|x1, x2, x3) = P(y2|x2, x3)⋅(P(x1y3|x2, x3))/(P(x1|x2, x3)) = P(y2|x2, x3)⋅(P(x1y3|x2, x3))/(P(x1))
Од 21↑ следи дека:
P(y3|x2, x3) = (P(y2, y3|x2x3)⋅P(y3|x1, x2, x3))/(P(y2, y3|x1, x2, x3))
P(x1, y2|y3, x2, x3) = P(x1)⋅P(y2|y3x1x2x3) = P(x1)⋅P(y2|y3x2x3)
P(x1, y2|y3, x2, x3) = P(x1)⋅P(y2|y3x1x2x3) = P(x1)⋅P(y2|y3x2x3)
\strikeout off\uuline off\uwave offP(y2, y3|x1, x2, x3)⋅P(y3|x2, x3) = P(y2, y3|x2, x3)⋅P(y3|x1, x2, x3)
P(y2, y3|x1, x2, x3) = P(y3)⋅P(y2|y3x1x2x3) = P(y3)⋅P(y2|y3x2x3)
P(y3)⋅P(y2|y3x2x3)⋅P(y3|x2, x3) = P(y2, y3|x2, x3)⋅P(y3|x1, x2, x3); P(y3)⋅\cancelP(y2y3|x2x3) = \cancelP(y2, y3|x2, x3)⋅P(y3|x1, x2, x3)
P(y3) = P(y3|x1, x2, x3)
P(y3)⋅P(y2|y3x2x3)⋅P(y3|x2, x3) = P(y2, y3|x2, x3)⋅P(y3|x1, x2, x3); P(y3)⋅\cancelP(y2y3|x2x3) = \cancelP(y2, y3|x2, x3)⋅P(y3|x1, x2, x3)
P(y3) = P(y3|x1, x2, x3)
Во изразот 22↑не гледам ништо спорно
P(x1, y2|y3, x2, x3) = P(x1|y3x2x3)⋅P(y2|x1, y3, x2, x3)\overset(b) = P(x1|y3, x2x3)⋅P(y2|y3, x2, x3)
(b) - y2 и x1 се статистички независни зошто C1(1, 2) = 0. (Да ама тоа изгледа не е доволен услов).
that is x1 and y2 are conditionally independent given y3; for each x2 and x3 fixed (⊛).
(Ова е суштинска констатација ама нешто матно ми изглеа како се стига до неа)
In terms of conditional uncertainties this means H(X1|Y3, x2, x3) = H(X1|Y2, Y3, x2, x3)
(ова е јасно ако се земе во предвид ⊛)
, therefore
R(1, 3|P(x1);x2, x3) = R[1, (2, 3)|P(x1);x2, x3)]
for all x2, x3 and P(x1). Hence C1(1, 3) = C1[1, (2, 3)]. This completes the proof.
Proof of Lemma 4.3. Let x3 be fixed and let a probability distribution P(x1, x2) on pairs of inputs x1 and x2 be given.
Let
I(X1;Y3|X2, x3) = H(Y3|X2, x3) − H(Y3|X1, X2, x3) =
⎲⎳x1x2y3p(x1, x2, y3)⋅log2⎛⎝(p(X1, Y3|X2, x3))/(p(X1|X2, x3)⋅p(Y3|X2, x3))⎞⎠ = E⎡⎣log2⎛⎝(p(X1, Y3|X2, x3))/(p(X1|X2, x3)⋅p(Y3|X2, x3))⎞⎠⎤⎦
= E⎡⎣log2⎛⎝(p(y3| x1, x2, x3))/(p(y3| x2, x3))⎞⎠⎤⎦
where the expected value is taken with respect to the distribution 19↑. Clearly
\mathchoiceI(X1;Y3|X2, x3)I(X1;Y3|X2, x3)I(X1;Y3|X2, x3)I(X1;Y3|X2, x3) = H(Y3|X2, x3) − H(Y3|X1, X2, x3) ≤ R[(1, 2), 3|P(x1, x2);x3)]\overset(a) = \mathchoiceI(X1X2;Y3|x3)I(X1X2;Y3|x3)I(X1X2;Y3|x3)I(X1X2;Y3|x3)
(a) ова е мое толкување за мапирање меѓу номенклатурата во T. Cover и Van. der Moulen.
\mathchoiceI(X1X2;Y3|x3)I(X1X2;Y3|x3)I(X1X2;Y3|x3)I(X1X2;Y3|x3) = I(X2;Y3|x3) + \mathchoiceI(X1;Y3|X2, x3)I(X1;Y3|X2, x3)I(X1;Y3|X2, x3)I(X1;Y3|X2, x3) ⇒ I(X1X2;Y3|x3) ≥ I(X1;Y3|X2, x3)
It is easily verified that
maxx2maxP(x1)R(1, 3|P(x1);x2, x3) = maxP(x1x2){H(Y3|X2, x3) − H(Y3|X1, X2, x3)}
Hence: C1(1, 3) ≤ C1[(1, 2), 3]
Now suppose C1(2, 3) = 0. This implies that for all x1, x3, y3 fixed \strikeout off\uuline off\uwave offP(y3|x1, x2, x3) stays same as as x2 varies\uuline default\uwave default. Or, if x3 is fixed, the matrix of conditional probabilities P(y3|x1|x2, x3) is the same for different x2.
C1(1, 3|x2x3) = maxP(x1)[R(1, 3|P(x1);x2x3)]
\strikeout off\uuline off\uwave off
R(1, 3|P(x1), x2, x3) = H(Y3) − H(Y3|X1|x2x3) = I(X1;Y3) = H(Y3) − H(Y3|X1) =
= − ⎲⎳y3p(y3) log2(p(y3)) − ⎲⎳x1y3p(x1)p(y3|x1|x2x3) log2(p(y3|x1|x2x3)
\strikeout off\uuline off\uwave offC1(1, 3|x2, x3) denotes the capacity of channel P(y3|x1|x2, x3) for x2 and x3 fixed. \uuline default\uwave defaultThus C1(1, 3|x2, x3) is the same for different x2. Consider now the channel formed by the conditional probabilities P(y3|x1, x2|x3) as x3 is fized and x1 and x2 vary. This matrix can be partitioned into identical subchannels P(y3|x1|x2x3) one coresponding to each valuex2. C1[(1, 2), 3|x3] = maxP(x1, x2)R((1, 2), 3|P(x1, x2);x3) denotes the capacity of channel P(y3|x1, x2|x3), x3 fixed. Because of the decomposition of the channel into identical matrices, the capacity C1[(1, 2), 3|x3] can be achieved by using a probability distribution P(x1, x2) which assigns probability one to an arbitrary but fixed value of x2 only. But then C1[(1, 2), 3|x3] = C1(1, 3|x2, x3) for all x2. Now maximizing with respct to x3 we obtain \strikeout off\uuline off\uwave offC1[(1, 2), 3] = C1(1, 3) which completes the proof of the lemma.
5 Definitions (encoding functions)
An encoding system of word length n ≥ 1 for transmitting M ≥ 1 messages from terminal 1 to terminal 3 over a d.m. three-terminal channel P(y1, y2, y3|x1, x2, x3) consist of:
(i) M encoding functions F1(m), m = 1, ..., M, at terminal 1
\mathchoiceF1(m) = {f01(m), f11(m, y11), ..., fn − 11(m, y11, ..., y1, n − 1)}F1(m) = {f01(m), f11(m, y11), ..., fn − 11(m, y11, ..., y1, n − 1)}F1(m) = {f01(m), f11(m, y11), ..., fn − 11(m, y11, ..., y1, n − 1)}F1(m) = {f01(m), f11(m, y11), ..., fn − 11(m, y11, ..., y1, n − 1)}
(ii) one strategy F2 at terminal 2
\strikeout off\uuline off\uwave off\mathchoiceF2(m) = {x21, f12(x21, y21), ..., fn − 12(x21, .., x2, n − 1;y21, ..., y2, n − 1)}F2(m) = {x21, f12(x21, y21), ..., fn − 12(x21, .., x2, n − 1;y21, ..., y2, n − 1)}F2(m) = {x21, f12(x21, y21), ..., fn − 12(x21, .., x2, n − 1;y21, ..., y2, n − 1)}F2(m) = {x21, f12(x21, y21), ..., fn − 12(x21, .., x2, n − 1;y21, ..., y2, n − 1)}
(iii) one strategy F3 at terminal 3
\strikeout off\uuline off\uwave off\mathchoiceF3(m) = {x31, f13(x31, y31), ..., fn − 13(x31, ..., x3, n − 1;y31, ..., y3, n − 1)}F3(m) = {x31, f13(x31, y31), ..., fn − 13(x31, ..., x3, n − 1;y31, ..., y3, n − 1)}F3(m) = {x31, f13(x31, y31), ..., fn − 13(x31, ..., x3, n − 1;y31, ..., y3, n − 1)}F3(m) = {x31, f13(x31, y31), ..., fn − 13(x31, ..., x3, n − 1;y31, ..., y3, n − 1)}
The encoding system is used as follows. The strategies F2 and F3 are fixed beforehand so as to optimize the transmission from terminal 1 to terminal 3 of an arbitrarily selected message m. If the message m is selected the sender at terminal 1 uses the strategy F1(m). The function fk − 11 specifies the next input x1k at terminal 1 on the basis of the message m to be transmitted an the observed outputs y11, ..., y1, k − 1 at terminal 1 up to the current time k − 1. Instead of using the encoding function F1(m) for a given message m we shall often use a sequence X1(m) of input letters which do not depend on the received letters at terminal 1, i.e., X1(m) = (x11, ..., x1n) ∈ An1. The function fk − 12 specifies the next input letter x2k at terminal 2 on the basis of the transmitted sequence x21, ..., x2, k − 1 and the received sequence y21, ..., y2, k − 1 at terminal 2 up to the current time.
\mathchoicextk = fk − 1t(xt1, .., xt, k − 1;yt1, ..., yt, k − 1)xtk = fk − 1t(xt1, .., xt, k − 1;yt1, ..., yt, k − 1)xtk = fk − 1t(xt1, .., xt, k − 1;yt1, ..., yt, k − 1)xtk = fk − 1t(xt1, .., xt, k − 1;yt1, ..., yt, k − 1)
Similarly the function fk − 13 determines the input x3k as a function of previous inputs x31, ..., x3, k − 1 and preivous outputs y31, ..., y3, k − 1 at terminal 3. As a special case we shall often take the strategy F3 to be a sequence X3 of input letters which do not depend on the received letters at terminal 3, i.e., X3 = (x31, ..., x3n) ∈ An3.
(Забележи дека само за терминалот 2 нема специјален кејс. Претпоставувам дека тоа е така затоа што тој терминал е само реле.)
To a given encoding system of word length n for transmitting M messages from terminal 1 to terminal 3 there corresponds a decoding system at terminal 3, consisting of M disjoint subsets of Bn3: D1, ..., DM. If the received sequence y31, ..., y3n lies in Dj the person at terminal 3 decides message j was sent at terminal 1.
(Замисли сценарио слично на проблемот од T. Cover EIT со повторување на влезните симболи-имаше пример со три бита)
Together an encoding and decoding system constitute a code. In order to compute the error probability for a given code we first need the conditional probabilities for operating the channel n times with the strategies F1(m), F2 and F3.
For this purpose we define for a given d.m. three terminal channel P(y1, y2, y3|x1, x2, x3) and each n ≥ 1 a derived three-terminal channel Kn. An input letter at terminal t for the derived channel Kn is a strategy Ft for choosing a sequence of n consecutive inputs to the memoryless channel P(y1y2y3|x1x2x3). Thus
where \strikeout off\uuline off\uwave offfn − 1t(xt1, ...xt, n − 1;yt1, ..., yt, n − 1) represents any function from the first k − 1 transmitted input letters and the first k − 1 observed output letters at terminal t into the next input letter xtk and xt1 is the first transmitted letter of the sequence; t = 1, 2, 3.
An output letter for channelKn at terminal t is is an n-tuple Yt = (yt1, ..., ytn) ∈ Bnt. The conditional probability of receiving the output (Y1, Y2, Y3) over channel Kn if the input (F1F2F3) is sent, is denoted by Pn(Y1Y2Y3|F1F2F3) and is precisely the probability of receiving \strikeout off\uuline off\uwave off(Y1, Y2, Y3) during n operations of the memoryless channel P(y1, y2, y3|x1x2x3) if the inputs to this channel are determined by the strategies F1, F2 and F3. Thus channel Kn is itself a d.m. three-terminal channel with channel probabilities defined by:
(24)
1Pn(Y1Y2Y3|F1F2F3)
= n∏k = 1P{y1ky2k, y3k|fk − 11(x11, ..., x1, k − 1;y11, ..., y1, k − 1);fk − 12(x21, ..., x2, k − 1;y21, ..., y2, k − 1);
fk − 13(x31, ..., x3, k − 1;y31, ..., y3, k − 1)}
A special case of the derived channel Kn arises if the strategies F1, F2 and F3 are replaced by sequences X1X2 and X3 , respectively, of tinput letters whic do not depend on the received letters at each particular terminal, i.e., Xt = (xt1, ..., Xtn) ∈ Ant; t = 1, 2, 3. The derived channel then reduces to the memoryless n-extension of P(y1, y2, y3|x1x2x3) which has conditionla probabilitties defined by 1↑. Channel K1 is identical with:
P(y1, y2, y3|x1x2x3).
To the three-terminal channel Kn there correspond vairous collections of subchannels similar to the subchannels defined in Section 2 in connection with the single channel P(Y1Y2Y3|F1F2F3) by keeping the input strategies at one or two terminals fixeed at particular choices. We consider here three different tuypes of subchannels.
(i) For each fixed pair of strategies (F2, F3) the collection of conditional probabilities Pn(Y3|F1|F2F3) defiened by:
(25) Pn(Y3|F1|F2F3) = ⎲⎳Y1Y2Pn(Y1Y2Y3|F1F2F3)
is a d.m channel with inputs F1 and outputs Y3. Its capacity is denoted by Cn(1, 3|F2F3) and
Cn(1, 3) = maxF2F3Cn(1, 3|F2F3)
(ii) For each fixed pair of strategies (F2, F3) the collection of conditional probabilities Pn(Y2Y3|F1|F2F3) defiened by:
(26) Pn(Y2Y3|F1|F2F3) = ⎲⎳Y1Pn(Y1Y2Y3|F1F2F3)
is a d.m channel with inputs F1 and outputs (Y2Y3). Its capacity is denoted by Cn(1, 3|F2, F3) and
Cn(1, (2, 3)) = maxF2F3Cn(1, (2, 3)|F2F3)
(iii) For each fixed pair of strategies F3 the collection of conditional probabilities Pn(Y3|F1F2|F3) defiened by:
(27) Pn(Y3|F1F2|F3) = ⎲⎳Y1Y2Pn(Y1Y2Y3|F1F2F3)
is a d.m channel with inputs (F1, F2) and outputs Y2. Its capacity is denoted by Cn((1, 2), 3|F3) and
Cn(1, (2, 3)) = maxF3Cn((1, 2), 3|F3)
The error probability for a given code will now be defined with the aid of the conditioal probabilitties 25↑. A (1, 3) -code (n, M, λ) for transmission of any of M ≥ 1 messages of word length n from terminal 1 to terminal 3 over a d.m three-terminal channel P(y1, y2, y3|x1, x2, x3) consist of M encoding functions F1(1), ..., F1(M) at terminal 1; a pair of fixed strategies F2 and F3 at terminals 2 and 3, respectively; and M decoding subsets D1, ..., DM at terminal 3 such that
⎲⎳y3 ∈ DmPn(Y3|F1(m)|F2, F3) ≥ 1 − λ for m = 1, ..., M
Thus, using such a code, the probability that any message transmitted at terminal 1 will be decoded incorrectly at terminal 3 is ≤ λ. A number R(1, 3) ≥ 0 is called an attainable rate for transmission in the 1 − 3 direction over a d.m. three-teminal channel K if there exists a sequence of (1, 3)-codes (n, Mn, λn) for K with Mn ≥ 2nR(1, 3) and such that λn → 0.
The transmisstion capacity for sending in the 1-3 direction over channel K is denoted by \mathchoice(1, 3)(1, 3)(1, 3)(1, 3) and deifined as the upper bound of the set of attainable rates R(1, 3).
The capacities Cn(1, 3), Cn[1, (2, 3)] , and Cn[(1, 2), 3] above are defined analogously to the single-letter capacities C1(1, 3), C1[1, (2, 3)] and C1[(1, 2), 3]. They correspond to one operation of the derived d.m. channel Kn. Therefore all inequalityies of Section 4 for single letter capacities carry over to coresponding inequalities for n-letter capacities. In particular, it follows from Lemmas 4.1 and 4.3 that, for all n ≥ 1,
and
Cn(1, 3) is the capacity of the „best” d.m. channel Pn(Y3|F1|F2, F3) as F2 and F3 vary over strategies of length n. The memoryless k-extension of this best channel is a d.m. channel of the form Pnk(Y3|F1|F2, F3) with capacity equal to k⋅Cn(1, 3) . The capacity of the best d.m. channel Pnk(Y3|F1|F2F3) as F2 and F3 vary over strategies of length nk is equal to Cnk(1, 3). The strategies of length nk include as special cases those strategies whose functional influence involves only blocks of length n. Therefore
(30) \mathchoice(Cn(1, 3))/(n) ≤ (Cnk(1, 3))/(nk)(Cn(1, 3))/(n) ≤ (Cnk(1, 3))/(nk)(Cn(1, 3))/(n) ≤ (Cnk(1, 3))/(nk)(Cn(1, 3))/(n) ≤ (Cnk(1, 3))/(nk)
for all positive integers n and k.
Ова ми се коси со доказот на Theorem 7.3 доколку n=k=1.
The channel capacity for transmition in the 1 − 3 direction is for any d.m three-terminal channel defined by
in section 7 is shown that C(1, 3) is actually the transmission capacity for sending from terminal 1 to termina 3, i.e, (1, 3) = C(1, 3). It is a consequence of Theorems 7.1and 7.2 below that
(32) \mathchoiceC(1, 3) = limn → ∞(Cn(1, 3))/(n)C(1, 3) = limn → ∞(Cn(1, 3))/(n)C(1, 3) = limn → ∞(Cn(1, 3))/(n)C(1, 3) = limn → ∞(Cn(1, 3))/(n)
In next sextion we establish a necessary and sufficient condition under whih C(1, 3) > 0.
6 A necessary and sufficient condition for a positive channel capacity
In this section we derive the following necessary and sufficient condition for positive channel capacity.
C(1, 3) > 0 if and only if both C1[1, (2, 3)] > 0 and C1[(1, 2), 3] > 0. Alternatively, C(1, 3) = 0 if eather C1[1, (2, 3)] = 0 or C1[(1, 2), 3] = 0.
MMV
For the proof we shall need Lemmas 6.1 and 6.2 below.
If C1[1, (2, 3)] = 0 then Cn[1, (2, 3)] = 0 for all n ≥ 1. Similarly, if C1[(1, 2)3] = 0 then Cn[(1, 2), 3] = 0 for all n ≥ 1.
Proof. We only prove the first statement. Let \strikeout off\uuline off\uwave offC1[1, (2, 3)] = 0. \uuline default\uwave defaultThis implies that for each fixed pair (y2, y3) the conditional probability P(y2, y3|x1x2x3) remains the same as x1 varies\strikeout off\uuline off\uwave off
Дали тоа значи дека всушност y2, y3 не зависат од x1??? Така всушност ќе излезе дека I(X1;Y2Y3) = 0. Да токму тоа значи. Види изведување подолу.
.
I(X1;Y2Y3) = H(Y2Y3) − H(Y2Y3|X1) = H(Y2Y3) − ∑x1y2y3p(x1)⋅p(y2y3|x1)log(p(y2y3|x1) = H(Y2Y3) − \canceltoH(Y2, Y3)(∑y2y3p(y2y3|x1)log(p(y2y3|x1))⋅\cancelto1∑x1p(x1)
\strikeout off\uuline off\uwave offWe need to show Cn[1, (2, 3)] = 0 for all n ≥ 1, i.e., for each fixed pair of strategies (F2, F3) the d.m. channel Pn(Y2, Y3|F1|F2, F3) has identical rows as F1 varies over all inputs strategies at terminal 1. From 24↑ and 25↑ we have
\strikeout off\uuline off\uwave offPn(Y1Y2Y3|F1F2F3) = ∏nk = 1P{y1ky2k, y3k|fk − 11fk − 11(x11, ..., x1, k − 1;y11, ..., y1, k − 1);fk − 12(x21, ..., x2, k − 1;y21, ..., y2, k − 1);fk − 13(x31, ..., x3, k − 1;y31, ..., y3, k − 1)}
(33) Pn(Y2Y3|F1|F2F3) = ⎲⎳Y1Pn(Y1Y2Y3|F1F2F3)
Pn(Y2Y3|F1|F2F3) = ⎲⎳y11y12, ...y1nn∏k = 1P{y1ky2k, y3k|fk − 11(x11, ..., x1, k − 1;y11, ..., y1, k − 1);fk − 12(x21, ..., x2, k − 1;y21, ..., y2, k − 1);fk − 13(x31, ..., x3, k − 1;y31, ..., y3, k − 1)}
Let now n, F2, F3, Y2 and Y3 all be fixed. Since C1[1, (2, 3)] = 0,
P(y2k, y3k|fk − 11(x11, ..., x1, k − 1;y11, ..., y1, k − 1)fk − 12(x11, ..., x1, k − 1;y11, ..., y1, k − 1);fk − 13(x11, ..., x1, k − 1;y11, ..., y1, k − 1));
does not depend on the actual value of \strikeout off\uuline off\uwave offfk − 11(x11, ..., x1, k − 1;y11, ..., y1, k − 1) therefore 33↑ can be rewriten as
Pn(Y2Y3|F1|F2F3) = ∏nk = 1P{y2k, y3k|fk − 12(x21, ..., x2, k − 1;y21, ..., y2, k − 1);fk − 13(x31, ..., x3, k − 1;y31, ..., y3, k − 1)}
where the input sequence X1 = (x11, ..., x1n) is chosen arbitrarily. This holds for all choices of F1, thus Pn(Y2Y3|F1|F2F3) stays same as F1 varies. This completes the proof of the first part of the lemma (Cn[1, (2, 3)] = 0). The proof of the second part is very similar.
If C1(1, 3) = 0, C1[1, (2, 3)] > 0 and C1(2, 3) > 0 then \mathchoiceC2(1, 3) > 0C2(1, 3) > 0C2(1, 3) > 0C2(1, 3) > 0
Proof. C1[1, (2, 3)] > 0 implies there exists a pair (x20, x30) of input letters and a pair (y20, y30) of output letter at terminals 2 and 3 and two different input letters x1i and x1j at terminal 1 such that
αi = P(y20, y30|x1i, x20, x30) ≠ P(y20, y30|x1j, x20, x30) = αj,
(Ова следи од \strikeout off\uuline off\uwave offC1[1, (2, 3)] > 0)
say.
Now
\mathchoiceC1(1, 3) = 0 implies P(y30|x1i,x20,x30)=P(y30|x1j,x20,x30)C1(1, 3) = 0 implies P(y30|x1i,x20,x30)=P(y30|x1j,x20,x30)C1(1, 3) = 0 implies P(y30|x1i,x20,x30)=P(y30|x1j,x20,x30)C1(1, 3) = 0 implies P(y30|x1i,x20,x30)=P(y30|x1j,x20,x30)
Let
βi = P(y30|x1i, x20, x30) − P(y20, y30|x1i, x20, x30) and βj = P(y30|x1j, x20, x30) − P(y20, y30|x1j, x20, x30).
P(y30|x1i, x20, x30) ≥ P(y20, y30|x1i, x20, x30) затоа што во \strikeout off\uuline off\uwave offP(y30|x1i, x20, x30) се добива со сумирање на P(y20, y30|x1i, x20, x30) по сите вредности на y20.
Then βj − βi = αi − αj ≠ 0.
βj − βi = \canceltoP(y30|x1i, x20, x30) = P(y30|x1j, x20, x30)P(y30|x1j, x20, x30) − P(y20, y30|x1j, x20, x30) − \cancelP(y30|x1i, x20, x30) + P(y20, y30|x1i, x20, x30) = P(y20, y30|x1i, x20, x30) − P(y20, y30|x1j, x20, x30) = αi − αj
Since \mathchoiceC1(2, 3) > 0C1(2, 3) > 0C1(2, 3) > 0C1(2, 3) > 0 there exist input letter x10’ and x30’ at terminal 1 and terminal 3 , respectively, one output letter y30’ at terminal 3 and two different input letters x2k and x2l at terminal 2, such that \mathchoiceck = P(y30’|x10’, x2k, x30’) ≠ P(y30’|x10’, x2l, x30’) = clck = P(y30’|x10’, x2k, x30’) ≠ P(y30’|x10’, x2l, x30’) = clck = P(y30’|x10’, x2k, x30’) ≠ P(y30’|x10’, x2l, x30’) = clck = P(y30’|x10’, x2k, x30’) ≠ P(y30’|x10’, x2l, x30’) = cl, say. Clearly
We will now show the exisstence of a d.m channel of the form P2(Y3|F1|F2, F3) which has at least two different rows and therefore
(каналната матрицa треба да има различни редици за да капацитетот е различен од 0 (а не транспонираната канална матрица). Види изведуање во box-от подолу)
has capacity different form zero. The strategy \mathchoiceF2 = {x21, f12(y21)}F2 = {x21, f12(y21)}F2 = {x21, f12(y21)}F2 = {x21, f12(y21)} is defined by \mathchoicex21 = x20x21 = x20x21 = x20x21 = x20 and
⎡⎢⎢⎢⎣
p(y1)
p(y2)
p(y3)
⎤⎥⎥⎥⎦ = ⎡⎢⎢⎢⎣
p11
p21
p31
p12
p22
p32
p13
p23
p33
⎤⎥⎥⎥⎦⎡⎢⎢⎢⎣
p(x1)
p(x2)
p(x3)
⎤⎥⎥⎥⎦ ∑3j = 1p(yj|xi) = ∑3j = 1pi, j = 1 i = 1, 2, 3 кога ќе пратиш некој влезен симбол на излезмора да добиеш нешто!!!
⎡⎢⎢⎢⎣
p(y1)
p(y2)
p(y3)
⎤⎥⎥⎥⎦ = ⎡⎢⎢⎢⎣
p1
p2
p3
p1
p2
p3
p1
p2
p3
⎤⎥⎥⎥⎦⎡⎢⎢⎢⎣
p(x1)
p(x2)
p(x3)
⎤⎥⎥⎥⎦
p(y1) = ∑3i = 1pip(xi) p(y2) = ∑3i = 1pip(xi) p(y3) = ∑3i = 1pip(xi) ⇒ p(y1) = p(y2) = p(y3)
H(Y) = log2(M) = log(3)
H(Y|X) = ∑ip(xi)⋅H(Y|xi) = p(x1)⋅H(Y|x1) + p(x2)⋅H(Y|x2) + p(x3)⋅H(Y|x3) = p(x1)⋅3⋅p1log2((1)/(p1)) + p(x2)⋅3⋅p2log2((1)/(p2)) + p(x3)⋅3⋅p3log2((1)/(p3)) ≠ H(Y) ⇒ C > 0
Значи треба нетранспонираната канална матрица да има исти редици за да капацитетот биде 0!!!
⎡⎢⎢⎢⎣ p(y1) p(y2) p(y3) ⎤⎥⎥⎥⎦ = ⎡⎢⎢⎢⎣ p1 p1 p1 p2 p2 p2 p3 p3 p3 ⎤⎥⎥⎥⎦⎡⎢⎢⎢⎣ p(x1) p(x2) p(x3) ⎤⎥⎥⎥⎦ Π = ⎡⎢⎢⎢⎣ p1 p2 p3 p1 p2 p3 p1 p2 p3 ⎤⎥⎥⎥⎦
p(y1) = p1 p(y2) = p2 p(y3) = p3 ⇒ H(Y) = ∑3i = 1pilog2((1)/(pi))
H(Y|X) = ∑ip(xi)⋅H(Y|xi) = p(x1)⋅H(Y|x1) + p(x2)⋅H(Y|x2) + p(x3)⋅H(Y|x3) = p(x1)⋅∑3i = 1pilog2((1)/(pi)) + p(x2)⋅∑3i = 1pilog2((1)/(pi)) + p(x3)⋅∑3i = 1pilog2((1)/(pi)) = ∑3i = 1pilog2((1)/(pi))
H(Y|X) = H(Y) ⇒ C = H(Y) − H(Y) = 0
p(y1) = ∑3i = 1pip(xi) p(y2) = ∑3i = 1pip(xi) p(y3) = ∑3i = 1pip(xi) ⇒ p(y1) = p(y2) = p(y3)
H(Y) = log2(M) = log(3)
H(Y|X) = ∑ip(xi)⋅H(Y|xi) = p(x1)⋅H(Y|x1) + p(x2)⋅H(Y|x2) + p(x3)⋅H(Y|x3) = p(x1)⋅3⋅p1log2((1)/(p1)) + p(x2)⋅3⋅p2log2((1)/(p2)) + p(x3)⋅3⋅p3log2((1)/(p3)) ≠ H(Y) ⇒ C > 0
Значи треба нетранспонираната канална матрица да има исти редици за да капацитетот биде 0!!!
⎡⎢⎢⎢⎣ p(y1) p(y2) p(y3) ⎤⎥⎥⎥⎦ = ⎡⎢⎢⎢⎣ p1 p1 p1 p2 p2 p2 p3 p3 p3 ⎤⎥⎥⎥⎦⎡⎢⎢⎢⎣ p(x1) p(x2) p(x3) ⎤⎥⎥⎥⎦ Π = ⎡⎢⎢⎢⎣ p1 p2 p3 p1 p2 p3 p1 p2 p3 ⎤⎥⎥⎥⎦
p(y1) = p1 p(y2) = p2 p(y3) = p3 ⇒ H(Y) = ∑3i = 1pilog2((1)/(pi))
H(Y|X) = ∑ip(xi)⋅H(Y|xi) = p(x1)⋅H(Y|x1) + p(x2)⋅H(Y|x2) + p(x3)⋅H(Y|x3) = p(x1)⋅∑3i = 1pilog2((1)/(pi)) + p(x2)⋅∑3i = 1pilog2((1)/(pi)) + p(x3)⋅∑3i = 1pilog2((1)/(pi)) = ∑3i = 1pilog2((1)/(pi))
H(Y|X) = H(Y) ⇒ C = H(Y) − H(Y) = 0
Thus the first input letter at terminal 2 is held at x20 and the second input letter is x2k or x2l according to wheter the first observed output letter y21 was equal to y20 or not. The strategy \mathchoiceF3 = {x31, f13}F3 = {x31, f13}F3 = {x31, f13}F3 = {x31, f13} is defined by \mathchoicex31 = x30x31 = x30x31 = x30x31 = x30 and \mathchoicef13 = x’30f13 = x’30f13 = x’30f13 = x’30. The inputs F1 at terminal 1 are chosen to be sequences X1 = (x11x12) of input letters. For this choice of F2 and F3 and for every \mathchoiceX1 = (x11, x12)X1 = (x11, x12)X1 = (x11, x12)X1 = (x11, x12) and \mathchoiceY3 = (y31, y32)Y3 = (y31, y32)Y3 = (y31, y32)Y3 = (y31, y32) we have:
\strikeout off\uuline off\uwave offPn(Y3|F1|F2F3) = ∑Y1Y2Pn(Y1Y2Y3|F1F2F3) ова е од 25↑
\strikeout off\uuline off\uwave offPn(Y1Y2Y3|F1F2F3) = ∏nk = 1P{y1ky2k, y3k|fk − 11(x11, ..., x1, k − 1;y11, ..., y1, k − 1);fk − 12(x21, ..., x2, k − 1;y21, ..., y2, k − 1);fk − 13(x31, ..., x3, k − 1;y31, ..., y3, k − 1)}
Вторава ако се замени во првава се добива:
\strikeout off\uuline off\uwave off
(36)
1
Pn(Y3|F1|F2F3) = ⎲⎳Y1Y2n∏k = 1P{y1ky2k, y3k|fk − 11(x11, ..., x1, k − 1;y11, ..., y1, k − 1);
fk − 12(x21, ..., x2, k − 1;y21, ..., y2, k − 1);fk − 13(x31, ..., x3, k − 1;y31, ..., y3, k − 1)}
1P2(Y3|F1|F2, F3)
= ⎲⎳y21, y22P(y21, y31|x11, x20, x30)⋅P(y22, y32|x12, f12(y21), x’30) =
= P(y32|x12, x2k, x’30)P(y20, y31|x11, x20, x30) + P(y32|x12, x2l, x’30)⋅\cancelto proof is below!!!{P(y31|x11, x20, x30) − P(y20, y31|x11, x20, x30)}
\strikeout off\uuline off\uwave offPn(Y3|F1|F2F3) = ∑Y1Y2∏nk = 1P{y1ky2k, y3k|fk − 11(x11, ..., x1, k − 1;y11, ..., y1, k − 1);fk − 12(x21, ..., x2, k − 1;y21, ..., y2, k − 1);fk − 13(x31, ..., x3, k − 1;y31, ..., y3, k − 1)}
Pn(Y3|F1|F2F3) = ∑Y2∏2k = 1P{y2k, y3k|fk − 11(x11, ..., x1, k − 1;y11, ..., y1, k − 1);fk − 12(x21, ..., x2, k − 1;y21, ..., y2, k − 1);fk − 13(x31, ..., x3, k − 1;y31, ..., y3, k − 1)}
F2 = {x21, f12(y21)} f12(y21) = ⎧⎨⎩
x2k
if y21 = y20
x2l
if y21 ≠ y20
1Pn(Y3|F1|F2F3)
= ⎲⎳y21y22P{y21, y31|f01(x11, x1, 0;y11, ..., y1, 0);f02(x21, ..., x2, 0;y21, ..., y2, 0);f03(x31, ..., x3, 0;y31, ..., y3, 0)}⋅
⋅P{y22, y32|f11(x11;y11);f12(x21;y21);f13(x31;y31)}
1 Pn(Y3|F1|F2F3)
= ⎲⎳y21y22P{y21, y31|\canceltox11 from F1 = (x11, x12)f01(x11, x1, 0;y11, y1, 0); \canceltox21 = x20 from F2 = {x21, f12(y21)}f02(x21, x2, 0;y21, y2, 0);
\canceltox31 = x30 from F3 = (x31, f13)f03(x31, x3, 0;y31, y3, 0)} ⋅ P{y22, y32|\canceltox12 from F1 = (x11, x12)f11(x11;y11);
\canceltof12(y21) from F2 = {x21, f12(y21)}f12(x21;y21); \canceltof13 = x’30 from F3 = (x31, f13)f13(x31;y31)}
Pn(Y3|F1|F2F3) = ⎲⎳y21y22P{y21, y31|x11, x20, x30}⋅P{y22, y32|x12;f12(y21);x30’}
(37) Pn(Y3|F1|F2F3) = P{y20, y31|x11, x20, x30}⋅P{y32|x12;\mathchoicex2kx2kx2kx2k;x30’} + {P{y31|x11, x20, x30} − P{y20, y31|x11, x20, x30}}P{y32|x12;\mathchoicex2lx2lx2lx2l;x30’}
Првиот член од сумата на LHS е за y21 = y20 a вторито член е за \strikeout off\uuline off\uwave offy21 ≠y20. Разликата на веројатности во вториот член потекнува од тоа \uuline default\uwave defaultшто првата веројатност е сума на веројатностите за сите вредности на y21\strikeout off\uuline off\uwave off (затоа y21 е елиминиран од здружената веројатност). Она што останува од разликата е всушност P{y21, y31|x11, x20, x30} за y21 ≠ y20.
Now choosing Y30 =(y30, y’30), X10 = (x1i, x’10) and X’10 = (x1j, x’10) one has P2(Y30|X10|F2F3) = ckαi + clβi.
\strikeout off\uuline off\uwave offck = P(y30’|x10’, x2k, x30’) ≠ P(y30’|x10’, x2l, x30’) = cl; αi = P(y20, y30|x1i, x20, x30) = P(y20, y30|x1j, x20, x30) = αj
βi = P(y30|x1i, x20, x30) − P(y20, y30|x1i, x20, x30) and βj = P(y30|x1j, x20, x30) − P(y20, y30|x1j, x20, x30).
\strikeout off\uuline off\uwave offPn(Y3 = Y30|F1 = X10|F2F3) = \mathchoiceP{y20, y31|\canceltox1ix11, x20, x30}P{y20, y31|\canceltox1ix11, x20, x30}P{y20, y31|\canceltox1ix11, x20, x30}P{y20, y31|\canceltox1ix11, x20, x30}⋅\mathchoiceP{\canceltoy’30y32|x12;x2k;x30’}P{\canceltoy’30y32|x12;x2k;x30’}P{\canceltoy’30y32|x12;x2k;x30’}P{\canceltoy’30y32|x12;x2k;x30’} + P{\canceltoy’30y32|x12;x2l;x30’}⋅{P{\canceltoy30y31|x11, x20, x30} − P{y20, y31|x11, x20, x30}} следи од: 37↑.
P2(Y30|X10|F2F3) = ckαi + clβi = \mathchoiceP(y30’|x10’, x2k, x30’)P(y30’|x10’, x2k, x30’)P(y30’|x10’, x2k, x30’)P(y30’|x10’, x2k, x30’)⋅\mathchoiceP(y20, y30|x1i, x20, x30)P(y20, y30|x1i, x20, x30)P(y20, y30|x1i, x20, x30)P(y20, y30|x1i, x20, x30) + P(y30’|x10’, x2l, x30’)⋅(P(y30|x1i, x20, x30) − P(y20, y30|x1i, x20, x30))
P2(Y30|X’10|F2F3) = ckαj + clβj = \mathchoiceP(y30’|x10’, x2k, x30’)P(y30’|x10’, x2k, x30’)P(y30’|x10’, x2k, x30’)P(y30’|x10’, x2k, x30’)⋅\mathchoiceP(y20, y30|x1j, x20, x30)P(y20, y30|x1j, x20, x30)P(y20, y30|x1j, x20, x30)P(y20, y30|x1j, x20, x30) + P(y30’|x10’, x2l, x30’)[P(y30|x1j, x20, x30) − P(y20, y30|x1j, x20, x30)]
\strikeout off\uuline off\uwave offP2(Y3 = Y30|F1 = X’10|F2F3) = \mathchoiceP{y20, \canceltoy30y31|\canceltox1jx11, x20, x30}P{y20, \canceltoy30y31|\canceltox1jx11, x20, x30}P{y20, \canceltoy30y31|\canceltox1jx11, x20, x30}P{y20, \canceltoy30y31|\canceltox1jx11, x20, x30}⋅\mathchoiceP{\canceltoy’30y32|x12;x2k;x30’}P{\canceltoy’30y32|x12;x2k;x30’}P{\canceltoy’30y32|x12;x2k;x30’}P{\canceltoy’30y32|x12;x2k;x30’} + P{\canceltoy’30y32|x12;x2l;x30’}⋅{P{\canceltoy30y31|x11, x20, x30} − P{y20, y31|x11, x20, x30}}
By 34↑ \strikeout off\uuline off\uwave offP2(Y30|X10|F2F3) ≠ P2(Y30|X’10|F2F3)
\strikeout off\uuline off\uwave offck(αi − αj) ≠ cl(βj − βi)
P2(Y30|X10|F2F3) − P2(Y30|X’10|F2F3) = ckαi + clβi − ckαj − clβj = ck(αi − aj) − cl(βj − βi) ≠ 0 ⇒ P(Y30|X10|F2F3)≠P2(Y30|X’10|F2F3)
hence the channel matrix P2(Y3|F1|F2F3) has at least two different rows. This implies that C2(1, 3) > 0 and thus completes the proof of the lemma
(Претпоставката на лемата дека \strikeout off\uuline off\uwave offC1[1, (2, 3)] > 0\uuline default\uwave default е вградена во αi ≠ αj)
.
Now we turn to the proof of Theorem 6.1. First suppose both C1[1, (2, 3)] > 0 and C1[(1, 2), 3] > 0. By Corollary 4.2, C1[(1, 2), 3] > 0 implies either \strikeout off\uuline off\uwave offC1(1, 3) > 0 or C(2, 3) > 0. If C1(1, 3) > 0 then by 30↑ C2(1, 3) > 0. If C1(1, 3) = 0 then C1(2, 3) > 0 and C2(1, 3) > 0 by Lemma 6.2. In either case C2(1, 3) > 0 and thus C1(1, 3) > 0 by 32↑. Conversely, suppose either \uuline default\uwave defaultC1[1, (2, 3)] = 0 or C1[(1, 2), 3] = 0. If C1[1, (2, 3)] = 0 then Cn[1, (2, 3)] = 0 for all n > = 1 by Lemma 6.1. Thus Cn(1, 3) = 0 for all n ≥ 1 by 28↑ and hence C(1, 3) = 0 by 31↑. Similar argument holds if \strikeout off\uuline off\uwave offC1[(1, 2), 3] = 0. This completes the proof of Theorem 6.1.
7 The coding Theorem and its week converse
We now shot that C(1, 3) is the actual transmission capacity for sending from terminal 1 to terminal 3, i.e., (1, 3) = C(1, 3). This result follows immedialtely form Theorems 7.1 and 7.2 below.
Let ϵ > 0 and 0 < λ ≤ 1 be arbitrary. For any d.m. three-terminal channel and all n sufficiently large there exists a (1, 3) -code (n, M, λ) with M > 2n[C(1, 3) − ϵ].
n⋅C(1, 3) − n⋅ϵ < log2(M) C(1, 3) < (1)/(n)⋅log2(M) + ϵ
\strikeout off\uuline off\uwave offR = (1)/(n)⋅log(M) ≤ C; M ≤ 2nC R = C − ϵ; M ≤ 2n(R + ϵ); R − ϵ < (1)/(n)⋅log(M); n⋅(R − ϵ) < log(M); 2n⋅(R − ϵ) < M
Proof. Let m be positive integer such that
Let F2 and F3 be two strategies of length m such that the corresponding d.m. channel Pm(Y3|F1|F2, F3) has capacity Cm(1, 3). First suppose \mathchoicen = k⋅mn = k⋅mn = k⋅mn = k⋅m, with k a positive integer. A code (k, M, λ) for the d.m.c Pm(Y3|F1|F2, F3) is clearly a (1, 3)-code (n, M, λ) for the d.m. three-terminal channel P(y1y2y3|x1x2x3). By [7] there exists, for all k sufficiently large, a code (k, M, λ) for channel Pm(Y3|F1|F2F3) with
M > 2k(Cm(1, 3) − t ⁄ 4) = 2n(Cm(1, 3) ⁄ m − t ⁄ 4m) > 2n(C(1, 3) − 3t ⁄ 4).
This proves the theorem for n of the form k⋅m.
Now suppose \mathchoicen = km + t 1 ≤ t < mn = km + t 1 ≤ t < mn = km + t 1 ≤ t < mn = km + t 1 ≤ t < m. Proceeding as before, there exists a code (k, M, λ) for the d.m.c. Pm(Y3|F1|F2, F3) with
M > 2(n − t)(C(1, 3) − 3⋅t ⁄ 4) = 2n⋅((n − t) ⁄ n)⋅(C(1, 3) − 3⋅t ⁄ 4) > 2n(C(1, 3) − t).
Ова не успеав да го докажам подолу!!!
Прв обид:
Втор обид:
((n − t) ⁄ n)⋅(C(1, 3) − 3⋅t ⁄ 4m) ≥ (1)/(n)(n − t)(C(1, 3) − 3⋅m ⁄ 4m) = (1)/(n)(n − t)(C(1, 3) − 3 ⁄ 4) = (1)/(n)(n − m)(C(1, 3) − 3 ⁄ 4) > (1)/(n)(n − mk)(C(1, 3) − 3 ⁄ 4) = (t)/(n)(C(1, 3) − 3 ⁄ 4)
Трет обид:
\mathchoiceM > 2(n − t)(C(1, 3) − 3⋅t ⁄ 4) = 2k⋅m(C(1, 3) − 3⋅t ⁄ 4) > 2k⋅m(C(1, 3) − t)M > 2(n − t)(C(1, 3) − 3⋅t ⁄ 4) = 2k⋅m(C(1, 3) − 3⋅t ⁄ 4) > 2k⋅m(C(1, 3) − t)M > 2(n − t)(C(1, 3) − 3⋅t ⁄ 4) = 2k⋅m(C(1, 3) − 3⋅t ⁄ 4) > 2k⋅m(C(1, 3) − t)M > 2(n − t)(C(1, 3) − 3⋅t ⁄ 4) = 2k⋅m(C(1, 3) − 3⋅t ⁄ 4) > 2k⋅m(C(1, 3) − t) ова е најблиску што може до доказ.
1((n − t) ⁄ n)⋅(C(1, 3) − 3⋅t ⁄ 4m)
= (1)/(n)(nC − 3⋅t⋅n ⁄ 4m − t⋅C − 3⋅t2 ⁄ 4m) = ⎛⎝C − 3⋅t ⁄ 4m − (t⋅C)/(n) − 3⋅t2 ⁄ (4⋅n⋅m)⎞⎠ = |t = n − km| =
⎛⎝C − 3⋅(n − km) ⁄ 4m − ((n − km)⋅C)/(n) − 3⋅(n − km)2 ⁄ (4⋅n⋅m)⎞⎠ = ⎛⎝C − (3⋅n)/(4m) + (3k)/(4) − C + (mk)/(n)C − (3⋅(n2 − 2nkm + k2m2))/(4⋅n⋅m)⎞⎠
Втор обид:
1((n − t) ⁄ n)⋅(C(1, 3) − 3⋅t ⁄ 4m)
≥ (1)/(n)(n − t)(C(1, 3) − 3⋅m ⁄ 4m) = (1)/(n)(n − t)⎛⎝C(1, 3) − (3)/(4)⎞⎠ = (1 − (t)/(n))⋅⎛⎝C(1, 3) − (3)/(4)⎞⎠ > (1 − (t)/(n))⋅(C(1, 3) − 1) = C(1, 3) − 1 − (t)/(n)⋅C(1, 3) + (t)/(n)
> C(1, 3) − 1 − (t)/(n)⋅C(1, 3) = |n = km + t| = C(1, 3) − (km + t)/(n) − (t)/(n)⋅C(1, 3) = C(1, 3) − (km)/(n) − (t)/(n)(1 + C(1, 3))
((n − t) ⁄ n)⋅(C(1, 3) − 3⋅t ⁄ 4m) ≥ (1)/(n)(n − t)(C(1, 3) − 3⋅m ⁄ 4m) = (1)/(n)(n − t)(C(1, 3) − 3 ⁄ 4) = (1)/(n)(n − m)(C(1, 3) − 3 ⁄ 4) > (1)/(n)(n − mk)(C(1, 3) − 3 ⁄ 4) = (t)/(n)(C(1, 3) − 3 ⁄ 4)
Трет обид:
\mathchoiceM > 2(n − t)(C(1, 3) − 3⋅t ⁄ 4) = 2k⋅m(C(1, 3) − 3⋅t ⁄ 4) > 2k⋅m(C(1, 3) − t)M > 2(n − t)(C(1, 3) − 3⋅t ⁄ 4) = 2k⋅m(C(1, 3) − 3⋅t ⁄ 4) > 2k⋅m(C(1, 3) − t)M > 2(n − t)(C(1, 3) − 3⋅t ⁄ 4) = 2k⋅m(C(1, 3) − 3⋅t ⁄ 4) > 2k⋅m(C(1, 3) − t)M > 2(n − t)(C(1, 3) − 3⋅t ⁄ 4) = 2k⋅m(C(1, 3) − 3⋅t ⁄ 4) > 2k⋅m(C(1, 3) − t) ова е најблиску што може до доказ.
\strikeout off\uuline off\uwave offM > 2(n − t)(C(1, 3) − 3⋅t ⁄ 4) > 2(n − m)(C(1, 3) − 3⋅t ⁄ 4) = 2n(C(1, 3) − 3⋅t ⁄ 4)⋅2 − t(C(1, 3) − 3⋅t ⁄ 4)
Четврти обид:
(Cnk(1, 3))/(nk) > (Cn(1, 3))/(n)
((n − t) ⁄ n)⋅(C(1, 3) − 3⋅t ⁄ 4) ≥ (1)/(n)(n − t)(C(1, 3) − 3⋅m ⁄ 4m) = (1)/(n)(n − t)(C(1, 3) − 3 ⁄ 4)
(Cnk(1, 3))/(nk) > (Cn(1, 3))/(n)
((n − t) ⁄ n)⋅(C(1, 3) − 3⋅t ⁄ 4) ≥ (1)/(n)(n − t)(C(1, 3) − 3⋅m ⁄ 4m) = (1)/(n)(n − t)(C(1, 3) − 3 ⁄ 4)
for all k sufficiently large. This completes the proof of the theorem.
For any d.m. three-terminal channel a (1, 3)-code (n, M, λ) statisfies
(39) logM ≤ (n⋅C(1, 3) + 1)/(1 − λ)
Proof. We actually have somewhat stronger inequality
(40) logM ≤ (n⋅Cn(1, 3) + 1)/(1 − λ)
As a consequence we nao have:
For any d.m. three-terminal channel we have
Proof. Let ϵ > 0 be arbitrary. From Theorem 7.1 and inequality 40↑ we have that for n sufficiently lareg
2n(C(1, 3) − ϵ) < 2Cn(1, 3) + nϵ
\strikeout off\uuline off\uwave off\mathchoiceR = (1)/(n)⋅log(M) ≤ C; M ≤ 2nC R = C − ϵ; M ≤ 2n(R + ϵ); R − ϵ < (1)/(n)⋅log(M); n⋅(R − ϵ) < log(M); 2n⋅(R − ϵ) < MR = (1)/(n)⋅log(M) ≤ C; M ≤ 2nC R = C − ϵ; M ≤ 2n(R + ϵ); R − ϵ < (1)/(n)⋅log(M); n⋅(R − ϵ) < log(M); 2n⋅(R − ϵ) < MR = (1)/(n)⋅log(M) ≤ C; M ≤ 2nC R = C − ϵ; M ≤ 2n(R + ϵ); R − ϵ < (1)/(n)⋅log(M); n⋅(R − ϵ) < log(M); 2n⋅(R − ϵ) < MR = (1)/(n)⋅log(M) ≤ C; M ≤ 2nC R = C − ϵ; M ≤ 2n(R + ϵ); R − ϵ < (1)/(n)⋅log(M); n⋅(R − ϵ) < log(M); 2n⋅(R − ϵ) < M
M > 2n[C(1, 3) − ϵ] logM ≤ (n⋅Cn(1, 3) + 1)/(1 − λ) (Cnk(1, 3))/(nk) > (Cn(1, 3))/(n)
n(C(1, 3) − ϵ) < Cn(1, 3) + nϵ; nC(1, 3) − nϵ < Cn(1, 3) + nϵ; nC(1, 3) − 2nϵ < Cn(1, 3); C(1, 3) − 2ϵ < (1)/(n)⋅Cn(1, 3);
This together with the definition of C(1, 3) implies
C(1, 3) − 2ϵ < (Cn(1, 3))/(n) ≤ C(1, 3)
for sufficiently large n . This proves the theorem.
8 Lower bounds on the capacity
The capacity C(1, 3) can be described by the limiting expression 32↑ which is hard to evaluate. In this section we derive several lower bonunds on C(1, 3) which are more easily evaluated since they involve a maximizing process over single inputs and outputs to the channel only. Define R1R2R3 and R4 as follows:
(43) R2 = ⎧⎨⎩
(C1(1, 2)C1(2, 3))/(C1(1, 2) + C1(2, 3)) ,
if C1(1, 2) > 0 and C1(2, 3) > 0
0
otherwise
(44) R3 = (C1[1, (2, 3)]⋅C1(2, 3))/(C1(2, 3) + logb2)
\strikeout off\uuline off\uwave off
(45) R4 = (C1[(1, 2), 3]⋅C1(1, 2))/(C1(1, 2) + loga2)
Here a2 and b2 denote the size of the input and ouptut alphabet respecitvely at terminal 2. We will show that R1, R2, R3 and R4 are lower bounds on C(1, 3) follows immediately form coding theorems 8.1 8.2 and 8.3 below. Which of the lower bounds is largest depends on the praticular channel under consideration. Numerical examples are given in 6↓. There we have evaluated for each example of Section 3 the lower bounds R1, R2, R3 and R4. In Section 9 another lower bound R5 is obtained, which applies only to channels with a certain symmetric structure. We have included in the table the values of R5 as well, for those examples (1 and 2) to which this bound applies. For sake of completnes we have includet in the tabel also for eqach example the values of the upper bounds U and U’ which are derived in Section 10. As can be seen form the table, it turns out that for each example the largest lower bound coincides wiht the smallest upper bound. The capacity C(1, 3) is clearly equal to the common value. The values of C(1, 3) are given in last column of the table.
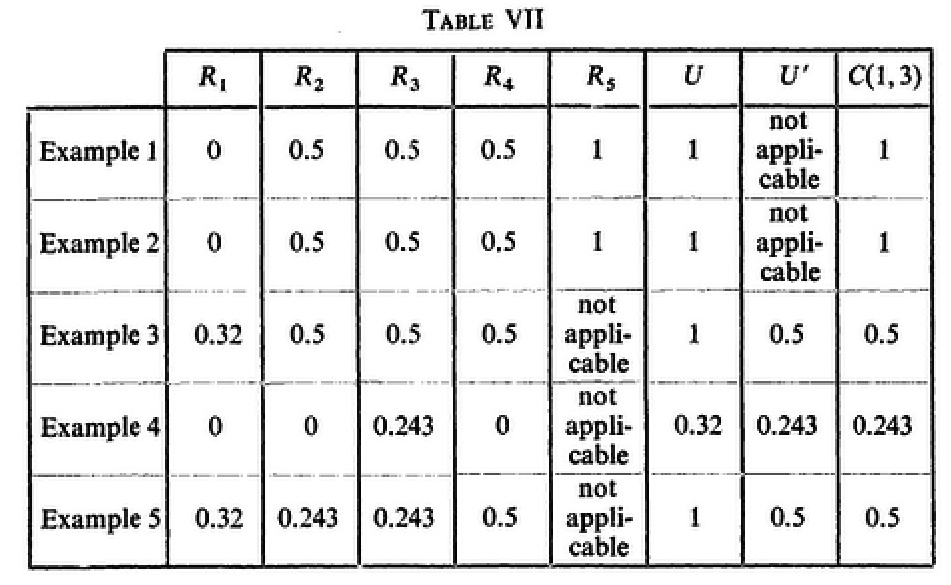
We now state and prove the coding theorems 8.1, 8.2 and 8.3.
Let ϵ > 0 and 0 ≤ λ ≤ 1 be arbitrary. For any d.m. three-terminal channel and all n sufficiently large there exists a (1, 3) -code (n, M, λ) with:
Proof. Assume C1(1, 2) > 0 and C1(2, 3) > 0. There exist a pair (x20, x30) of inputs letters such that the d.m.c. s1 with channel probabilities given by P(y2|x1|x20, x30) has capacity C1(1, 2). Let λ0 = (λ)/(2). For n1 sufficintly large there exists a code (n1, M1, λ0) for transmitting M1 codewords over s1 with rate arbitrarily close to C1(1, 2). Similarly there exists a pair (x10’, x30’) such that for n2 sufficienlty large there exists a code (n2, M2, λ0) with rate arbitrarily close to C1(2, 3) for d.m.c. s2 whose channel probabilities are defined by P(y3|x2|x10’, x30’). We chose n1 and n2 sufficiently large such that the above codes exist and such that
(MMV)
R = (1)/(n)⋅log(M) ≤ C; \mathchoiceM ≤ 2nCM ≤ 2nCM ≤ 2nCM ≤ 2nC R = C − ϵ; M ≤ 2n(R + ϵ); R − ϵ < (1)/(n)⋅log(M); n⋅(R − ϵ) < log(M); 2n⋅(R − ϵ) < M
Ако сакаш да нема грешки при преносот т.е. тие да бидат произволно мали треба да се придржуваш кон M ≤ 2nC.
Присети се на noisy typewriter!!! Тој ја грешеше секоја втора буква. Капацитетот на каналот е log2(13). Големината на кодната книга треба да биде M ≤ 2log2(13) = 13 . Со други зборови во приемникот во случај на ваков канал можеш да препознаеш најмногу 13 различни кодни симболи.
Ако сакаш да нема грешки при преносот т.е. тие да бидат произволно мали треба да се придржуваш кон M ≤ 2nC.
Присети се на noisy typewriter!!! Тој ја грешеше секоја втора буква. Капацитетот на каналот е log2(13). Големината на кодната книга треба да биде M ≤ 2log2(13) = 13 . Со други зборови во приемникот во случај на ваков канал можеш да препознаеш најмногу 13 различни кодни симболи.
The two codes may be combined to a (1, 3)-code (n1 + n2, M1, λ) in the following way. If the message m is to be sent from terminal 1 to terminal 3, first the m-th codeword of the first code is transmitted over channel s1. After n1 channel operations this message is decoded as message j, say, at terminal 2. Next the j-th codeword of the second code is sent at terminal 2, using channel s2. The received sequence of length n2 at terminal 3 is decoded as message k, say. Thus after n1 + n2 channel operations terminal 3 concludes that message k was originally sent at terminal 1. The total probability of an error in decoding is bounded by 2λ0 = λ. The code of length n1 + n2 with M1 codewords at terminal 1, consisting of all words of the first code followed by a sequence of n2 repetitions of the letter x10’ has a rate at least as large as R2 and error probability bounded by λ. This proves the theorem of n of the form n1 + n2 where n1 and n2 are chosen so as to satisfy 47↑. For general n we can reduce to the above case by transmitting, a few essentially dummy letters.
Let ϵ > 0 and 1 ≤ λ ≤ 1 be arbitrary. For any d.m. three-terminal channel and all n sufficiently large there exists a (1, 3)-code (n, M, λ) with
Proof. We proceed as in the proof of Theorem 8.1. Assume C1[1, (2, 3)] > 0 and C1(2, 3) > 0. There exist pair (x20, x30) of input letters such that the d.m.c s1 with channel probabilities P(y2, y3|x1|x20, x30) has capacity C1[1, (2, 3)] > 0. Let λ0 = (λ)/(2). For all n1 sufficiently large there exists code (n1, M1, λ0) for channel s1 with rate arbitrary close to \strikeout off\uuline off\uwave offC1[1, (2, 3)]. Similarly there exist a pair (x10’, x10’) such that for n2 sufficiently large there exists a code (n2, M2, λ0) with rate arbitrarily close to C1(2, 3) for the d.m.c s2 whose channel probabilities are given by P(y3|x2|x10’, x30’). We chose n1 and n2 sufficiently large such that above codes exist and such that the following inequalities are satisfied:
(50) M2 ≥ bn12
We now describe how these two codes can be combined to a (1, 3)-code (n1 + n2, M2, λ). If message m is to be sent from terminal 1 to terminal 3 the m-th codeword of the first code is transmitted over channel s1. A chance sequence (y21, ...y2n1) of n1 letters is received at terminal 2 and a sequence (y31, ..., y3n1) is received at terminal 3. Since M2 ≥ bn12 there exists a one-to-one mapping form the space of all received sequences at terminal 2 into the set of codewors of the second code. Supppose this mapping associates the j-th codeword of the second code with the sequence \strikeout off\uuline off\uwave off(y21, ...y2n1). Then this codeword is transmitted at terminal 2, using channel s2 ,during the next n2 channel operations. A chanel sequence (y3, n1 + 1, ..., y3, n1 + n2) is received at terminal 3 and is decoded into message i, say, using the decoding sets of the second code. If the above mapping associates the message i with the sequence (y21’, ..., y2n1’), terminal 3 concludes that this sequence was received at terminal 2 during the first n1 channel operations. Using the decoding sets of the first code terminal 3 decodes the sequence (y21’, ..., y2n’;y31, ..., y3n1) of n1 pairs of received symbols into message k, say. Terminal 3 then concludes that message k was originally sent at terminal 1. The total probability of an error in decoding is bounded by 2λ0 = λ. This proves the theorem for n of the form n1 + n2 where n1 and n2 are chosen so that 49↑ and 50↑ are satisfied. The case for general n can easily be reduced to the above case.
Let ϵ > 0 and 1 ≤ λ ≤ 1, be arbitrary. For any d.m. three-terminal channel and all n sufficiently large there exists a (1, 3)-code (n, M, λ) with
Proof. Proceeding as before we assume that C1(1, 2) > 0 and C1[(1, 2), 3] > 0. There exists a pari (x20, x30) of input letters such that the d.m.c. s_1 with channlel probabilities P(y2|x1|x20x30) has capacity C1(1, 2). Let λ0 = (λ)/(2). For al n1 sufficienlty large there exists a code (n1, M1, λ0) for channel s1 with rate arbitrarily close to C1(1, 2). similarly there exists an input letter x30’ such that for n2 sufficiently large there exist a code (n2, M2, λ0) with rate arbitrarily close to C1[(1, 2), 3] fro channel s2 whose channel probabilities are given by P(y3|x1x2|x30’). We choose n1 and n2 sufficiently large such that the above codes exist and such that the following inequalityies are satisfied:
(52) M1 ≥ an22
The two codes can be combined to a (1, 3)-code (n1 + n2, M2, λ) as follows. If the sender at terminal 1 wants to send message m to terminal 3 he looks up the m-th codeword of the secodn code. Each codeword of the second code consist of pair of input sequences each of length n2. Suppose the m-th codeword of the second code is the paricular sequence (x11, ..., x1n2;x21, ..., x2n2). In order to send theis codeword over channel s2, terminal 1 must put in the successive symbols x11, ..., x1n2 and terminal 2 must send the successive symbols x21, ..., x2n2. First however terminal 1 must instruct terminal 2 which sequence to send. Since M1 ≥ an22 there exists a one-to-one mapping from the set of all input sequences of length n2 at terminal 2 into the set of codewords of the fist code. Suppose this mapping associates with the particular sequence \strikeout off\uuline off\uwave offx21, ..., x2n2 during the next sequence of n2 channel operaitions, terminal 1 fist sends the j-th codeword of the first code over channel s1. A chane sequece (y21, ..., y2n1) is received at termina 2 and is decoded to message i , say, using the decoding sets of the first code. Suppose the above mapping associates the i-th codeword of the first code with the input sequence (x21’, ..., x2n2’) at terminal 2. Then, during the next n2 channel opеrations terminal 1 send the sequence (x11, ..., x1n2) and terminal 2 transmits simultaneously the sequence (x21’, ...x2n2’). A chance sequence (y31,..,y3n2) is received at terminal 3 and is decoded into message k, say, using the decoding sets of the second code. Terminal 3 concludes that message k , was originally intended by terminal 1. The total probability of an error in decoding is bounded by 2λ0 = λ. this proves the theorem for n of the form n1 + n2, where n1 and n2 are chosen so that 52↑ and 53↑ are satisfied. For general n we can easily reduce to the case above.
9 Three-terminal channels with symmetric structure
There are channels wich have a special symetric structure which permits terminal 1 and terminal 2 to transmit independently and simultaneously over the channel. In this case, if terminla 1 first sends his message to terminal 2 who then sends the received information on to terminal 3, terminal 1 can keep sending new message during the same time as terminal 2 sends the previous ones on to terminal 3. Thus, after wasting the initial n letters by sending the first message to termina 2, no further delay is caused in sending from terminal 1 to terminal 3. For an important class of channels this procedure leads to a new bound
\mathchoiceR5 = min(C1(1, 2), C1(2, 3))R5 = min(C1(1, 2), C1(2, 3))R5 = min(C1(1, 2), C1(2, 3))R5 = min(C1(1, 2), C1(2, 3))
which is an improvement over R2.
We first prove the following theorem:
suppose a d.m. three-terminal channel P(y1y2y3|x1x2x3) satisfies the following conditions:
(i) C1(1, 3) = 0
(ii) \strikeout off\uuline off\uwave offP(y2y3|x1x2x3) = P(y2|x1x2x3)P(y3|x1x2x3) for all x1, x2, x3, y2 and y3 .
(iii) There exists an input letter x30 and function g2:A2xB2 → A2, such that the d.m.c K(y32|x11|g2, x30) with inputs x11 and outputs y32 defined by
(54) K(y32|x11|g2, x30) = ⎲⎳y21P(y32|x12, g(x21, y21), x30)⋅P(y21|x11x21x30)
Мене ми изгледа дека P(y21|x11x21x30) = 1 зошто имаш ∑y21. Слични претпоставки имам во главното изведување подолу. Ако загледаш подобро изглда како усреднување по \strikeout off\uuline off\uwave offP(y21|x11x21x30) . \uuline default\uwave defaultСепак многу добро се уклопува во изведувањето подолу и мора да има некој сличен резон.
does not depend on x21. Then
(55) \mathchoiceC(1, 3) ≥ C{K(y32|x11|g2, x30)}C(1, 3) ≥ C{K(y32|x11|g2, x30)}C(1, 3) ≥ C{K(y32|x11|g2, x30)}C(1, 3) ≥ C{K(y32|x11|g2, x30)}
where \strikeout off\uuline off\uwave offC{K(y32|x11|g2, x30)} is capacity of channel K(y32|x11|g2, x30).
Proof. For each n ≥ 2 we construct a channel Pn(Y3|X1|F2, F3) by specifying F2 and F3 as follows. In 25↑ let
F2 = {x21, g2(x21, y21), ..., g2(x2, n − 1, y2, n − 1)}
\strikeout off\uuline off\uwave off
(ова е неуспешен обид)
\strikeout off\uuline off\uwave off
\strikeout off\uuline off\uwave off
Pn(Y3|F1|F2F3) = ⎲⎳Y1Y2Pn(Y1Y2Y3|F1F2F3)
Pn(Y1Y2Y3|F1F2F3) = n∏k = 1P{y1ky2k, y3k|fk − 11(x11, ..., x1, k − 1;y11, ..., y1, k − 1);fk − 12(x21, ..., x2, k − 1;y21, ..., y2, k − 1);
fk − 13(x31, ..., x3, k − 1;y31, ..., y3, k − 1)}
\strikeout off\uuline off\uwave off
Pn(Y3|F1|F2F3) = ⎲⎳Y1Y2n∏k = 1P{y1ky2k, y3k|fk − 11(x11, ..., x1, k − 1;y11, ..., y1, k − 1);
fk − 12(x21, ..., x2, k − 1;y21, ..., y2, k − 1);fk − 13(x31, ..., x3, k − 1;y31, ..., y3, k − 1)}
\strikeout off\uuline off\uwave off
P2(Y3|F1|F2, F3) = ⎲⎳y21, y22P(y21, y31|x11, x20, x30)⋅P(y22, y32|x12, f12(y21), x’30)
(ова е неуспешен обид)
\strikeout off\uuline off\uwave off
Pn(Y3|F1|F2F3) = ⎲⎳Y1Y2Pn(Y1Y2Y3|F1F2F3) = ⎲⎳Y2Pn(Y2Y3|F1F2F3) =
= ⎲⎳Y2n∏k = 1P{y2k, y3k|(x11, ..., x1k − 1), fk − 12(x21, ..., x2, k − 1;y21, ..., y2, k − 1), (x30, ..x30)} = n∏k = 1P{y3k|(x11, ..., x1k − 1), fk − 12(x21, ..., x2, k − 1;y21, ..., y2, k − 1), (x30, ..x30)}
= (y31|x11, x21, x30)⋅n∏k = 2P{y3k|(x11, ..., x1k − 1), fk − 11(x11, ..., x1, k − 1;y11, ..., y1, k − 1), (x30, ..x30)}
\strikeout off\uuline off\uwave off
1
Pn(Y3|F1|F2F3) = ⎲⎳Y1Y2Pn(Y1Y2Y3|F1F2F3) = ⎲⎳Y2Pn(Y2Y3|F1F2F3) =
= ⎲⎳Y2n∏k = 1P{y2k, y3k|(x11, ..., x1k − 1), fk − 12(x21, ..., x2, k − 1;y21, ..., y2, k − 1), (x30, ..x30)} =
= ⎲⎳Y2(y21, y31|x11, x21, x30)⋅n∏k = 2P{y2k, y3k|(x11, ..., x1k − 1), fk − 11(x11, ..., x1, k − 1;y11, ..., y1, k − 1), (x30, ..x30)}
= ⎲⎳Y2n∏k = 2P{y2k|(x11, ..., x1k − 1), fk − 11(x11, ..., x1, k − 1;y11, ..., y1, k − 1), (x30, ..x30)}⋅P{y3k|(x11, ..., x1k − 1), fk − 11(x11, ..., x1, k − 1;y11, ..., y1, k − 1), (x30, ..x30)}
where x21 is chosen arbitrary but fixed, and let F3 = {x30, ..., x30}. With this choice of F2 and F3, and for all X1 = (x11, ..., x1n) and Y3 = (y31, ..., y3n)
(56) \mathchoicePn(Y3|X1|F2, F3) = P(y31|x11, x21, x30)⋅n∏k = 2 ⎲⎳y2, k − 1P(y3k|x1k, g2(x2, k − 1, y2, k − 1), x30)⋅P(y2, k − 1|x1, k − 1, g2(x2, k − 2, y2, k − 2), x30)Pn(Y3|X1|F2, F3) = P(y31|x11, x21, x30)⋅n∏k = 2 ⎲⎳y2, k − 1P(y3k|x1k, g2(x2, k − 1, y2, k − 1), x30)⋅P(y2, k − 1|x1, k − 1, g2(x2, k − 2, y2, k − 2), x30)Pn(Y3|X1|F2, F3) = P(y31|x11, x21, x30)⋅n∏k = 2 ⎲⎳y2, k − 1P(y3k|x1k, g2(x2, k − 1, y2, k − 1), x30)⋅P(y2, k − 1|x1, k − 1, g2(x2, k − 2, y2, k − 2), x30)Pn(Y3|X1|F2, F3) = P(y31|x11, x21, x30)⋅n∏k = 2 ⎲⎳y2, k − 1P(y3k|x1k, g2(x2, k − 1, y2, k − 1), x30)⋅P(y2, k − 1|x1, k − 1, g2(x2, k − 2, y2, k − 2), x30)
(MMV!!! Oвде дефинитивно е докажан изразот 56↑!!!)
Да видам што се добива за k = 2:
Pn(Y3|X1|F2, F3) = P(y31|x11, x21, x30)∏nk = 2∑y2, k − 1P(y3k|x1k, g2(x2, k − 1, y2, k − 1), x30)⋅P(y2, k − 1|x1, k − 1, g2(x2, k − 2, y2, k − 2), x30) =
= P(y31|x11, x21, x30)∑y2, 1P(y32|x12, g2(x2, 1, y2, 1), x30)⋅P(y2, 1|x1, 1, g2(x2, 0, y2, 0), x30) =
\mathchoice = P(y31|x11, x21, x30)∑y2, 1P(y32|x12, g2(x2, 1, y2, 1), x30)⋅P(y2, 1|x1, 1, x21, x30) = P(y31|x11, x21, x30)∑y2, 1P(y32|x12, g2(x2, 1, y2, 1), x30)⋅P(y2, 1|x1, 1, x21, x30) = P(y31|x11, x21, x30)∑y2, 1P(y32|x12, g2(x2, 1, y2, 1), x30)⋅P(y2, 1|x1, 1, x21, x30) = P(y31|x11, x21, x30)∑y2, 1P(y32|x12, g2(x2, 1, y2, 1), x30)⋅P(y2, 1|x1, 1, x21, x30)
Да видам што се добива за k = 3:
Претпоставувам исто се добива и со:
Pn(Y3|X1|F2, F3) = P(y31|x11, x21, x30)∏nk = 2∑y2, k − 1P(y3k|x1k, g2(x2, k − 1, y2, k − 1), x30)⋅P(y2, k − 1|x1, k − 1, g2(x2, k − 2, y2, k − 2), x30) =
= P(y31|x11, x21, x30)∑y2, 1P(y32|x12, g2(x2, 1, y2, 1), x30)⋅P(y2, 1|x1, 1, g2(x2, 0, y2, 0), x30) =
\mathchoice = P(y31|x11, x21, x30)∑y2, 1P(y32|x12, g2(x2, 1, y2, 1), x30)⋅P(y2, 1|x1, 1, x21, x30) = P(y31|x11, x21, x30)∑y2, 1P(y32|x12, g2(x2, 1, y2, 1), x30)⋅P(y2, 1|x1, 1, x21, x30) = P(y31|x11, x21, x30)∑y2, 1P(y32|x12, g2(x2, 1, y2, 1), x30)⋅P(y2, 1|x1, 1, x21, x30) = P(y31|x11, x21, x30)∑y2, 1P(y32|x12, g2(x2, 1, y2, 1), x30)⋅P(y2, 1|x1, 1, x21, x30)
Да видам што се добива за k = 3:
Pn(Y3|X1|F2, F3) =
= P(y31|x11, x21, x30)n∏k = 2 ⎲⎳y2, k − 1P(y3k|x1k, g2(x2, k − 1, y2, k − 1), x30)⋅P(y2, k − 1|x1, k − 1, g2(x2, k − 2, y2, k − 2), x30) =
= P(y31|x11, x21, x30) ⎲⎳y21P(y32|x12, g2(x21, y21), x30)⋅\cancelto1P(y2, 1|x1, 1, g2(x2, 0, y2, 0), x30)⋅
⋅ ⎲⎳y22P(y33|x13, g2(x2, 2, y2, 2), x30)⋅\cancelto1P(y2, 2|x1, 3, g2(x2, 1, y2, 1), x30) =
= \mathchoiceP(y31|x11, x21, x30) ⎲⎳y21P(y32|x12, g2(x21, y21), x30)⋅ ⎲⎳y22P(y33|x13, g2(x22, y22), x30)P(y31|x11, x21, x30) ⎲⎳y21P(y32|x12, g2(x21, y21), x30)⋅ ⎲⎳y22P(y33|x13, g2(x22, y22), x30)P(y31|x11, x21, x30) ⎲⎳y21P(y32|x12, g2(x21, y21), x30)⋅ ⎲⎳y22P(y33|x13, g2(x22, y22), x30)P(y31|x11, x21, x30) ⎲⎳y21P(y32|x12, g2(x21, y21), x30)⋅ ⎲⎳y22P(y33|x13, g2(x22, y22), x30)
Претпоставувам исто се добива и со:
\mathchoiceX1 = (x11, ..., x1n), F2 = {x21, g2(x21, y21), ..., g2(x2, n − 1, y2, n − 1)}, F3 = {x30, ..., x30}X1 = (x11, ..., x1n), F2 = {x21, g2(x21, y21), ..., g2(x2, n − 1, y2, n − 1)}, F3 = {x30, ..., x30}X1 = (x11, ..., x1n), F2 = {x21, g2(x21, y21), ..., g2(x2, n − 1, y2, n − 1)}, F3 = {x30, ..., x30}X1 = (x11, ..., x1n), F2 = {x21, g2(x21, y21), ..., g2(x2, n − 1, y2, n − 1)}, F3 = {x30, ..., x30}
\strikeout off\uuline off\uwave off
\mathchoicePn(Y3|X1|F2F3) = ⎲⎳Y1Y2n∏k = 1P{y1ky2k, y3k|X1;{x21, g2(x21, y21), ..., g2(x2, n − 1, y2, n − 1)};{x30, ..., x30}}Pn(Y3|X1|F2F3) = ⎲⎳Y1Y2n∏k = 1P{y1ky2k, y3k|X1;{x21, g2(x21, y21), ..., g2(x2, n − 1, y2, n − 1)};{x30, ..., x30}}Pn(Y3|X1|F2F3) = ⎲⎳Y1Y2n∏k = 1P{y1ky2k, y3k|X1;{x21, g2(x21, y21), ..., g2(x2, n − 1, y2, n − 1)};{x30, ..., x30}}Pn(Y3|X1|F2F3) = ⎲⎳Y1Y2n∏k = 1P{y1ky2k, y3k|X1;{x21, g2(x21, y21), ..., g2(x2, n − 1, y2, n − 1)};{x30, ..., x30}}
n = 2
P2(Y3|F1|F2, F3) =
⎲⎳Y2\mathchoiceP(y21, y31|x11, x21, x30)P(y21, y31|x11, x21, x30)P(y21, y31|x11, x21, x30)P(y21, y31|x11, x21, x30)⋅P(y22, y32|x12, g2(x21, y21), x30) =
⎲⎳Y2\mathchoiceP(y21|x11, x21, x30)⋅P(y31|x11, x21, x30)P(y21|x11, x21, x30)⋅P(y31|x11, x21, x30)P(y21|x11, x21, x30)⋅P(y31|x11, x21, x30)P(y21|x11, x21, x30)⋅P(y31|x11, x21, x30)⋅P(y22, y32|x12, g2(x21, y21), x30) =
P(y31|x11, x21, x30) ⎲⎳y21y22P(y21|x11, x21, x30)⋅P(y22, y32|x12, g2(x21, y21), x30) =
P(y31|x11, x21, x30) ⎲⎳y21P(y21|x11, x21, x30)⋅ ⎲⎳y22P(y22, y32|x12, g2(x21, y21), x30) =
\mathchoiceP(y31|x11, x21, x30) ⎲⎳y21P(y21|x11, x21, x30)⋅P(y32|x12, g2(x21, y21), x30)P(y31|x11, x21, x30) ⎲⎳y21P(y21|x11, x21, x30)⋅P(y32|x12, g2(x21, y21), x30)P(y31|x11, x21, x30) ⎲⎳y21P(y21|x11, x21, x30)⋅P(y32|x12, g2(x21, y21), x30)P(y31|x11, x21, x30) ⎲⎳y21P(y21|x11, x21, x30)⋅P(y32|x12, g2(x21, y21), x30)
Значи на двата начини се добива истиот резултат. Претпоставувам дека 56↑ е само посебна форма од 36↑ .
n = 3
P(y31|x11, x21, x30)⋅ ⎲⎳y21y22y23 \oversetfor k = 1P(y21|x11, x21, x30)⋅\oversetfor k = 2P(y22, y32|x12, g2(x21, y21), x30)⋅\overset for k = 3P(y23, y33|x123, g2(x22, y22), x30) =
\strikeout off\uuline off\uwave off
P2(Y3|F1|F2, F3) = ⎲⎳y21y22y23P(y21, y31|x11, x21, x30)⋅P(y22, y32|x12, g2(x21, y21), x30)⋅P(y23, y33|x13, g2(x22, y22), x30) =
\strikeout off\uuline off\uwave off
⎲⎳y21y22P(y21, y31|x11, x21, x30)⋅P(y22, y32|x12, g2(x21, y21), x30)⋅ ⎲⎳y23P(y23, y33|x13, g2(x22, y22), x30) =
⎲⎳y21y22P(y21, y31|x11, x12, x30)⋅P(y22, y32|x12, g2(x21, y21), x30)⋅P(y33|x13, g2(x22, y22), x30) =
⎲⎳y21P(y21, y31|x11, x12, x30)⋅ ⎲⎳y22[P(y33|x13, g2(x22, y22), x30)⋅P(y22, y32|x12, g2(x21, y21), x30)] =
⎲⎳y21P(y21, y31|x11, x12, x30)⋅P(y32|x12, g2(x21, y21), x30)⋅ ⎲⎳y22P(y33|x13, g2(x22, y22), x30) =
⎲⎳y21\cancelto1P(y21|x11, x12, x30)⋅P(y31|x11, x12, x30)⋅P(y32|x12, g2(x21, y21), x30)⋅ ⎲⎳y22P(y33|x13, g2(x22, y22), x30) =
= \mathchoiceP(y31|x11, x12, x30) ⎲⎳y21P(y32|x12, g2(x21, y21), x30)⋅ ⎲⎳y22P(y33|x13, g2(x22, y22), x30)P(y31|x11, x12, x30) ⎲⎳y21P(y32|x12, g2(x21, y21), x30)⋅ ⎲⎳y22P(y33|x13, g2(x22, y22), x30)P(y31|x11, x12, x30) ⎲⎳y21P(y32|x12, g2(x21, y21), x30)⋅ ⎲⎳y22P(y33|x13, g2(x22, y22), x30)P(y31|x11, x12, x30) ⎲⎳y21P(y32|x12, g2(x21, y21), x30)⋅ ⎲⎳y22P(y33|x13, g2(x22, y22), x30)
(For k = 2 , g2(x2, k − 2, y2, k − 2) = x21.) Since P(y31|x11, x21, x30) does not depend on x11
(заради тоа што C(1, 3) = 0)
the capacity of channel Pn(Y3|X1|F2F3) is equal to \mathchoice(n − 1)C{K(y32|x11|g2, x30)}(n − 1)C{K(y32|x11|g2, x30)}(n − 1)C{K(y32|x11|g2, x30)}(n − 1)C{K(y32|x11|g2, x30)}
Претпоставувам дека ова лесно ќе се докаже ако се напише преносната матрица. Затоа што мислам дека е очигледно го оставам за понатаму.
by theorem of [3]
(оваа теорема вели дека за проширување со должина n капацитетот е nC)
.
Hence
Овде се работи за Cn затоа што имаш Pn(...) каде Y3 и X1 се случајни процеси.
And letting n tend to infinity (32↑)
This completes the proof of the theorem.
Examples 1 and 2 of Section 3 clearly satisfy the conditions of Theorem 9.1 In Example 1 chose x30 arbitrary and definite g2 by g2(y2) = y2 for all y2. Then the channel probabilities
K(y32|x11|g2, x30) = ⎲⎳y21P(y32|x12, g2(y21), x30)⋅P(y21|x11)
are independent of x21 and constitute together a noisles binary channel with capacity equal to one. Thus C(1, 3) = C{K(y32|x11|g2, x30)} = 1. also, in this particular example, one has Cn(1, 3) = n − 1 for all n ≥ 1, and thus C(1, 3) = C2(1, 3). In Example 2 choose x30 = 0 and define g2 by g2(x2, y2) = x2 + y2(\mod2). Then channel probabilities
K(y32|x11|g2, x30) = ⎲⎳y21P(y32|x12, g(x21, y21), x30)⋅P(y21|x11x21)
are again independent of x21
не ми изгледа така? Тоа е согласно условите на Theorem 9.1.
and consitute a noisless binary channel with capacity equal to one. Thus, also in Example 2,
C(1, 3) = C{K(y32|x11|g2, x30)} = 1
A given channel satisfies condition (iii) of Theorem 9.1 if for every input x3 the various matrices {P(y2|x1|x2|x3)} can be obtained from each other, for different x2, by permutions of the columns. That is, whenever any pair of input letters x2 is interchanged there exists a corresponding relabeling of the output letters y2 which leaves the set of probabilitiies P(y2|x1|x2|x3) the same, for each x3 fixed. If such a symmmetry exists in the channel, then choose x20 and x30 arbitrarily and let g2(x20, y2) be any function form B2 into A2. For and x2 different from x20 weh obtain g2(x2, y2) by fist applying the permutation hx2(y2) which carries P(y2|x1|x20|x30) over into P(y2|x1|x2|x30) to the y2 in g2(x20, y2) thus g2(x2, y2) = g2(x20, hx(y2)). Using this function g2 the set of conditional probabilities K(y32|x11|g2, x30) does not depend on x21. In order to get rid of the dependence of y2 on x3 we assume for convinience also that \mathchoiceC1(3, 2) = 0C1(3, 2) = 0C1(3, 2) = 0C1(3, 2) = 0. We now have
\strikeout off\uuline off\uwave offSuppose a d.m. three-terminal channel P(y1, y2, y3|x1, x2, x3) satisfies the follownig conditions:
(i) C1(1, 3) = C1(3, 2) = 0
(ii) \strikeout off\uuline off\uwave offP(y2y3|x1x2x3) = P(y2|x1x2x3)P(y3|x1x2x3) for all x1, x2, x3, y2 and y3 .
(iii) For every pair of input letters x2 which is interchanged there exists a permutation of the output letters y2 which leaves the set of conditional probabilities P(y2|x1|x2) unchanged.
(59) \mathchoiceC(1, 3) ≥ R5 = min(C1(1, 2), C1(2, 3))C(1, 3) ≥ R5 = min(C1(1, 2), C1(2, 3))C(1, 3) ≥ R5 = min(C1(1, 2), C1(2, 3))C(1, 3) ≥ R5 = min(C1(1, 2), C1(2, 3))
P(y2, y3|x1x2x3) = P(y2|x1x2x3)⋅P(y3|x1x2x3) = P(y2|x1x2)⋅P(y3|x2x3)
Proof. Since C(1, 3) = C1(3, 2) = 0 we may write \mathchoiceP(y2, y3|x1x2x3) = P(y2|x1x2)⋅P(y3|x2x3)P(y2, y3|x1x2x3) = P(y2|x1x2)⋅P(y3|x2x3)P(y2, y3|x1x2x3) = P(y2|x1x2)⋅P(y3|x2x3)P(y2, y3|x1x2x3) = P(y2|x1x2)⋅P(y3|x2x3). For each x2 the capacity of channel P(y2|x1|x2) is equal to C1(1, 2), by condition (iii). Chose x20 arbitrary but fixed. Let x30 be such that the d.m.c. P(y3|x2|x30) has capacity C1(2, 3). Let X20 = (x20, ..., x20) and X3 = (x30, .., x30). Let 0 ≤ λ ≤ 1, be arbitrary and λ0 = (λ)/(2). Select n sufficiently large such that there exists a code (n, M, λ0) for channel P(y2|x1|x20) and such that there exists a code (n, M, λ0) for channel P(y3|x2|x30) both wiht rate close to R5. We then have M distinct codewords at terminal 1; X1(1), ..., X1(M);X1(m) ∈ An1; and M disjoint decoding subsets D2(1), ...D2(M) at terminal 2; D2(m) ⊂ Bn2. Similarly we have M distinct codewors at terminal 2; X2(1), ...X2(M); X2(m) ∈ An2; and M disjoint decoding subsets D3(1), ..., D3(M) at terminal 3; D3(m) ⊂ Bn3. The probability of an error in decoding is for each code bounded by λ0. For all X1 = (x11, ..., x1n), X2 = (x21, ..., x2n) \strikeout off\uuline off\uwave offY2 = (y21, ..., y2n) and Y3 = (y31, ..., y3n) let:
Pn(Y2|X1X2)
= n∏k = 1P(y2k|x1k, x2k)
Pn(Y3|X2X3)
= n∏k = 1P(y3k|x12k, x3k)
Observe that condition (iii) also implies that if X20 is interchanged with any other sequence X2 = (x21, ..., x2n) then there exists a premutation hx2 of the output sequence Y2 = (y21, ..., y2n) which carries the set of probabilities Pn(Y2|X1|X20) into the set of probabilities Pn(Y2|X1|X2). Thus for each X2 and Y2, there exist hX2(Y2) such:
Pn(hX2(Y2)|X1X2) = Pn(Y2|X1X2)
for all X1. Now define a funciton g2:An2xBn2 → An2 by
g2(X2Y2) = X2(m) if
hX2(Y2) ∈ D2(m), m = 1, ...M.
Define the d.m.c Kn(Y3|X1|g2, X30) with inputs X1 and outputs Y3 by
Clearly
for all X2 and thus the channel is independent of X2. Therefore the d.m. three-terminal channel Pn(Y1, Y2, Y3|X1X2X3) satisfies the conditions of Theorem 9.1. For n sufficienlty large the system {X1(m), D3(m);m = 1, ..., M} forms a code (1, M, λ) for channel Kn(Y3|X1|g2, X30). Thus for ϵ > 0 and n sufficiently large
Applying Theorem 9.1 to cha\strikeout off\uuline off\uwave offPn(Y1, Y2, Y3|X1X2X3) we obtain
C(1, 3) ≥ R5
which completes the proof of the theorem.
Examples 1 and 2 of Section 3 clearly stisfy the conditions of theorem 9.2. Thus again for bot examples C(1, 3) = min(C1(1, 2), C1(2, 3)) = 1. Another example fo the same type is the channel with transition probabilities as follows. Al inputs and outputs are binary. Let P(y2, y3|x1x2x3) = P(y2|x1, x2)⋅P(y3|x2x3) for all x1, x2, x3, y2 adn y3. If x2 = 0, the channel P(y2|x1|x2) is binary symettric channel wiht probability of error p, say. If x2 = 1, the channel P(y2|x1|x2) is b.s.c. with probability of error 1 − p. Thus
P(y2 = 1|x1 = 0, x2 = 0)
= P(y2 = 0|x1 = 1, x2 = 0)
= P(y2 = 0|x1 = 0, x2 = 1)
= P(y2 = 1|x1 = 1, x2 = 1) = p
For all x3 the channel P(y3|x2|x3) is b.s.c with probabilty of error s, say. If we interchange the input letters x2 and simultaneously interchange the output letters y2 the channel P(Y2|X1|X2) remains unaltered. Accoriding to the analysis of Theorem 9.2, \mathchoiceC(1, 3) ≥ min(1 − H(p), 1 − H(s))C(1, 3) ≥ min(1 − H(p), 1 − H(s))C(1, 3) ≥ min(1 − H(p), 1 − H(s))C(1, 3) ≥ min(1 − H(p), 1 − H(s)) where H(p) = − p⋅log2(p) − (1 − p)⋅log2(1 − p). In Section 10 it is shown that the capacity of this channel is in fact equal to min(1 − H(p), 1 − H(s)).
10 Upper bounds on the capacity
In this section it is shown that C1[1, (2, 3)] and C1[(1, 2), 3] are both an upper bound on the capacity C1(1, 3). If the structure of a particular channel is such that one of these upper bounds coincides with one of the lower bounds, then the capacity of that channel is equal to this common value. This is the case if the channel has sufficient symetric structure. This result yields an important class of channels for which the capacity C(1, 3) can be determined with relative ease. If we define
we have the following
For any n a (1, 3)-code (n, M, λ) satisfies
(64) logM ≤ (n⋅U + 1)/(1 − λ)
This theorem clearly implies (1, 3) ≤ U , i.e. , U is an upper bound on the capacity C(1, 3). In proving Theorem 10.1 let a (1, 3)-code (n, M, λ) be given for transmission over the channel from terminal 1 to terminal 3. This code is a code (1, M, λ) for some d.m.c Pn(Y3|F1|F2F3) where the pair (F2, F3) is fixed. Let the input distribution (on strategies F1 of length n) for this d.m.c be deined by the uniform distribution on messages (numbered from 1 to M). As usual we denote by \mathchoiceH(m) − H(m|Yn3)H(m) − H(m|Yn3)H(m) − H(m|Yn3)H(m) − H(m|Yn3) the amount of information received through the channel if this particular code and input distribution are used. We intend ot show that for all choices of F2 and F3
From this and Fano’s inequality [7]
\strikeout off\uuline off\uwave offH(W|Ŵ) = H(W) − P(ϵ)log2nR = H(W) − P(ϵ)n⋅R
the desired result follows. In proving the inequlaities 65↑ and 66↑. we employ the technique of Shannon [5], i.e. we will consider the change in equivocation of message due to the next received letter at terminal 3. Let Ykt denote the sequence (yt1, ..., ytk) of k received letters at terminal t; t = 1, 2, 3; k = 1, ..., n; and let x1k, x2k, x3k denote the k-th transmitted letters. also assume F2 and F3 are arbitrary but fixed. We first prove 65↑. Proceeding as Shannon in [5] and [6] we have:
H(m) − H(m|Yn3) ≤ H(m) − H(m|Yn2, Yn3) = n⎲⎳k = 1{H(m|Yk − 12, Yk − 13) − H(m|Yk2, Yk3)}
∑2k = 1{H(m|Yk − 12, Yk − 13) − H(m|Yk2, Yk3)} = H(m|Y02, Y03) − \cancelH(m|Y12, Y13) + \cancelH(m|Y12, Y13) − H(m|Y22, Y23) = H(m) − H(m|Y22Y23) = H(m) − H(m|Yn2, Yn3)
Внатрешните членови секогаш се поништуваат остануваат само првиот и последниот. Го имам негде видено но не знам каде(веројатно EIT). (MMV)
Внатрешните членови секогаш се поништуваат остануваат само првиот и последниот. Го имам негде видено но не знам каде(веројатно EIT). (MMV)
From the basic inequalitiew of information theory we also obtain:
H(m|Yk − 12, Yk − 13) − H(m|Yk2, Yk3) = H(y2k, y3k|Yk − 12, Yk − 13) − H(y2k, y3k|m, Yk − 12, Yk − 13) ≤ |
conditioning reduces entropy
|
\strikeout off\uuline off\uwave off = H(y2k, y3k|Yk − 12, Yk − 13) − H(y2k, y3k|m, Yk − 11, Yk − 12, Yk − 13)\overset(a) ≤ H(y2k, y3k|x2k, y3k) − H(y2k, y3k|m, x1k, x2k, x3k) ≤ I(m;y2k, y3k|x1kx2kx3k) ≤ C[1, (2, 3)]
H(m|Yk − 12Yk − 13) − H(m|Yk2Yk3) = H(m|Yk − 12Yk − 13) − H(m|Yk − 12Yk − 13y2k, y3k) = I(m;y2k, y3k|Yk − 12Yk − 13) = H(y2k, y3k|Yk − 12Yk − 13) − H(y2k, y3k|m, Yk − 12Yk − 13)
(a) мислам дека потекнува од H(f(X)) ≤ H(X) H(X, f(X)) = H(X) + \cancelto0H(f(X)|X) = H(f(X)) + H(X|f(X))
(a) мислам дека потекнува од H(f(X)) ≤ H(X) H(X, f(X)) = H(X) + \cancelto0H(f(X)|X) = H(f(X)) + H(X|f(X))
\strikeout off\uuline off\uwave offFt(m) = {xt1, f1t(xt1, yt1), ..., fk − 1t(xt1, .., xt, k − 1;yt1, ..., yt, k − 1)} \mathchoicextk = fk − 1t(xt1, .., xt, k − 1;yt1, ..., yt, k − 1)xtk = fk − 1t(xt1, .., xt, k − 1;yt1, ..., yt, k − 1)xtk = fk − 1t(xt1, .., xt, k − 1;yt1, ..., yt, k − 1)xtk = fk − 1t(xt1, .., xt, k − 1;yt1, ..., yt, k − 1)
H(y2k, y3k|Yk − 12, Yk − 13) = H[P(y2k, y3k|Yk − 12, Yk − 13)] P(y2k, y3k|F2, F3)P(y2k, y3k|Yk − 12, Yk − 13)
H(X|Y) ≥ H(X|Y, f(Y)) = H(X|f(Y))
Ова подолу во засега ми држи најмногу вода:
H(y2k, y3k|Yk − 12, Yk − 13) ≥ H(y2k, y3k|Xk − 12, Yk − 12, Xk − 13Yk − 13) = H(y2k, y3k|f(Xk − 12, Yk − 12), f(Xk − 13Yk − 13)) = H(y2k, y3k|x2k, x3k)
H(y2k, y3k|m, x1k, x2k, x3k) ≤ H(y2k, y3k|m, Yk − 11, Yk − 12, Yk − 13) ова е логично зошто x2k = f(x21...x2k − 1;y21...y2k − 1) , со оглед на тоа што во RHS не ги знаеш x21, ...x2k − 1 логчно е таа неизвесност да биде поголема. Истото се добива ако се оди и со горниот доказ. Е сеа дали разликата е поголема тоа е под знак прашање.
H(X|Y) ≥ H(X|Y, f(Y)) = H(X|f(Y))
Ова подолу во засега ми држи најмногу вода:
H(y2k, y3k|Yk − 12, Yk − 13) ≥ H(y2k, y3k|Xk − 12, Yk − 12, Xk − 13Yk − 13) = H(y2k, y3k|f(Xk − 12, Yk − 12), f(Xk − 13Yk − 13)) = H(y2k, y3k|x2k, x3k)
H(y2k, y3k|m, x1k, x2k, x3k) ≤ H(y2k, y3k|m, Yk − 11, Yk − 12, Yk − 13) ова е логично зошто x2k = f(x21...x2k − 1;y21...y2k − 1) , со оглед на тоа што во RHS не ги знаеш x21, ...x2k − 1 логчно е таа неизвесност да биде поголема. Истото се добива ако се оди и со горниот доказ. Е сеа дали разликата е поголема тоа е под знак прашање.
This proves 66↑.
We thus showed that C1[1, (2, 3)] and C1[(1, 2), 3] are upper bounds on the capacity C(1, 3). We now investigate the consequences of this result for channels with symmetric structure.
(i) If a channel has sufficiently symetric structure that it satisfies the conditions of Theorem 9.2 then, by Lemmas 4.2 and 4.4, C1(1, 2) = C1[1, (2, 3)] and C1(2, 3) = C1[(1, 2), 3]. From this it follows immediately that for such a channle C(1, 3) = R5 = U. Thus in Examples 1 and 2 of Section 3 the capacity of either channel is equal to one. The capacity of the channel in the last paragraph of Section 9 is exactly Equal to min(1 − H(p), 1 − H(s)).
(ii) If channel satisfies C1(1, 2) = 0 and for all x1, x2, x3, y2 and y3, P(y2, y3|x1x2x3) = P(y2|x1x2x3)⋅P(y3|x1x2x3) then by Lemma 4.1 C(1, 3) = C1(1, 3) = C1[1, (2, 3)].
(iii) If a channel satisfies C1(2, 3) = 0, then, by Lemma 4.3 C(1, 3) = C1(1, 3) = C1[(1, 2), 3].
Examples of the last two types are quite trivial. In either case terminal 2 cannot help in the transmission procedure, other than transmtting the same letter each period.
For some channels the largest lower bound L = max(R1, R2, R3, R4, R5) coincides wiht U and then the capacity of the channel is determined. Fro other channels the values of L and U are clearly different, as is the case in Examples 3, 4 and 5 of Section 3 6↑, and then the capacity C(1, 3) is still undetermined. For an important class of channels, however, which are not of the type (i), (ii), or (iii) above, it is possible to derive another upper bound smaller than U, namely
(67) U’ = (C1[1, (2, 3)]⋅C1[(1, 2), 3])/(C1[1, (2, 3)] + C1[(1, 2), 3])
This upper boudn applies to the Examples 3, 4 and 5 of Section 3 and in fact equalst the best lower bound in each case, and hence the capacity C(1, 3) for these channels is again eaual to this common value L = U’. We argue as follows. Suppose a channel is not of the type (i) above and assume also that C1(1, 3) < C(1, 3). That is , suppose we know that the best transmission procedure for sending from terminal 1 to termina 3 must involve strategies at terminal 2, but also we know that terminal 2 cannot send to terminal 3 independently of terminal 1. Examples 3, 4 and 5 clearly satisfy these assumptions. Thus, at best, during n1 transmission periods the input x2 is fixed, and terminal 1 sens information to the pair to terminals 2 and 3, and during n − n1 transmission periods terminals 1 and 2 send jointly to terminal 3. Then the change in equivocation of message at terminal 3, due to the next received letter is equal to zero for n1 transmission periods. The only positive change in equivocation at terminla 3 is due to the n − n1 letters received when the inputs at terminal 2 are random. That is:
Also, the largest possible change in equivocation at terminal 3 is equal to the change in equivocation of message at terminals 2 and 3 due to the received letters y2 and y3 during the n1 transmission periods terminal 1 sends information away. That is, (n − n1)⋅C1[(1, 2), 3] is at most equal to n1⋅C1[1, (2, 3)] or
H(m) − H(m|Yn3) ≤ (C1[1, (2, 3)]⋅C1[(1, 2), 3])/(C1[1, (2, 3)] + C1[(1, 2), 3])
As in Theorem 10.1, this shows that U’ is an upper bound on C(1, 3) for the particular type of channels for which „timesharing” is best. This also proves that for Example 3 of Section 3 the capacity is exactly equal to 0.5, for Example 4 C(1, 3) = 0.243 and for Example 5 C(1, 3) = 0.5.
References
[1] Ash. R B. (1965) Information Theory. Interscience , New York.
[2] Fano, R. M. (1952) (1954) Statistical theory of communication. Notes on a course given at the Massachusetts Institute of Technology
[3] Feinstein, A. (1958) Foundations of Information Theory. McGraw Hill, New York.
[4] C. E. Shannon, (1948) A mathematical theory of communication,” BeN Syst. Tech. J., vol. 27, pp. 379-423, July 1948.
[5] C. E. Shannon, (1958) Channels with side information at the transmitter. IBM J. Res. Develop. 2, 289-293.
[6] C. E. Shannon, (1958) Two way communication channels. Proc. Fourt Berkley Symp. math. Statist. and Prob, 1, 611-644
[7] J. Wolfowitz, Coding Theorems of Information Theory, New York: Springer-Verlag, Third Ed., 1964.